 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCGL: Temporal Contrastive Graph for Self-supervised Video Representation Learning
Paper and Code
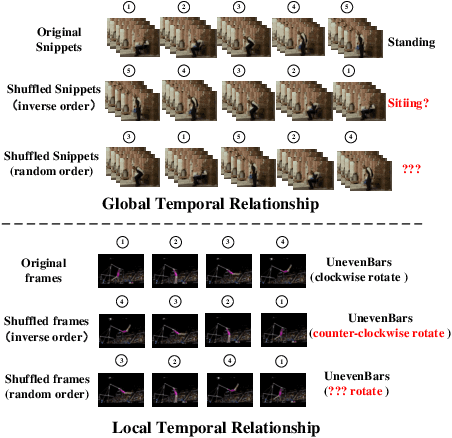
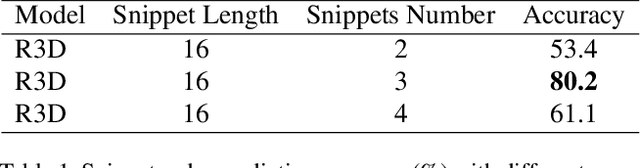
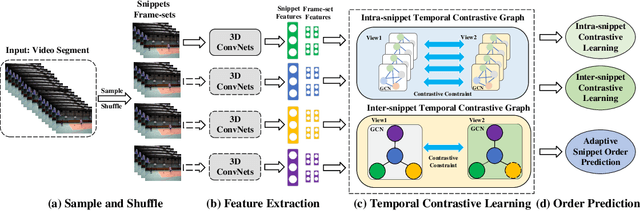

Video self-supervised learning is a challenging task, which requires significant expressive power from the model to leverage rich spatial-temporal knowledge and generate effective supervisory signals from large amounts of unlabeled videos. However, existing methods fail to increase the temporal diversity of unlabeled videos and ignore elaborately modeling multi-scale temporal dependencies in an explicit way. To overcome these limitations, we take advantage of the multi-scale temporal dependencies within videos and proposes a novel video self-supervised learning framework named Temporal Contrastive Graph Learning (TCGL), which jointly models the inter-snippet and intra-snippet temporal dependencies for temporal representation learning with a hybrid graph contrastive learning strategy. Specifically, a Spatial-Temporal Knowledge Discovering (STKD) module is first introduced to extract motion-enhanced spatial-temporal representations from videos based on the frequency domain analysis of discrete cosine transform. To explicitly model multi-scale temporal dependencies of unlabeled videos, our TCGL integrates the prior knowledge about the frame and snippet orders into graph structures, i.e., the intra-/inter- snippet Temporal Contrastive Graphs (TCG). Then, specific contrastive learning modules are designed to maximize the agreement between nodes in different graph views. To generate supervisory signals for unlabeled videos, we introduce an Adaptive Snippet Order Prediction (ASOP) module which leverages the relational knowledge among video snippets to learn the global context representation and recalibrate the channel-wise features adaptively. Experimental results demonstrate the superiority of our TCGL over the state-of-the-art methods on large-scale action recognition and video retrieval benchmarks.The code is publicly available at https://github.com/YangLiu9208/TCGL.