 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-SKNet with GridMask for Low-complexity Classification of Acoustic scene
Paper and Code
Oct 05, 2022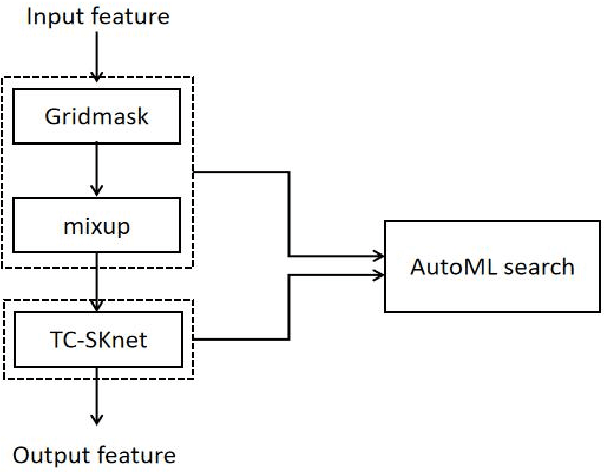



Convolution neural networks (CNNs) have good performance in low-complexity classification tasks such as acoustic scene classifications (ASCs). However, there are few studies on the relationship between the length of target speech and the size of the convolution kernels. In this paper, we combine Selective Kernel Network with Temporal-Convolution (TC-SKNet) to adjust the receptive field of convolution kernels to solve the problem of variable length of target voice while keeping low-complexity. GridMask is a data augmentation strategy by masking part of the raw data or feature area. It can enhance the generalization of the model as the role of dropout. In our experiments, the performance gain brought by GridMask is stronger than spectrum augmentation in ASCs. Finally, we adopt AutoML to search best structure of TC-SKNet and hyperparameters of GridMask for improving the classification performance. As a result, a peak accuracy of 59.87% TC-SKNet is equivalent to that of SOTA, but the parameters only use 20.9 K.