 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Imbalance for GNNs
Paper and Code
Oct 17, 2021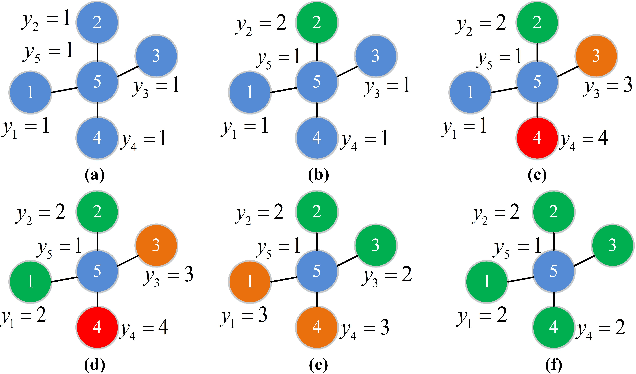
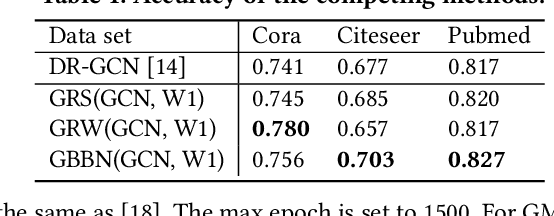
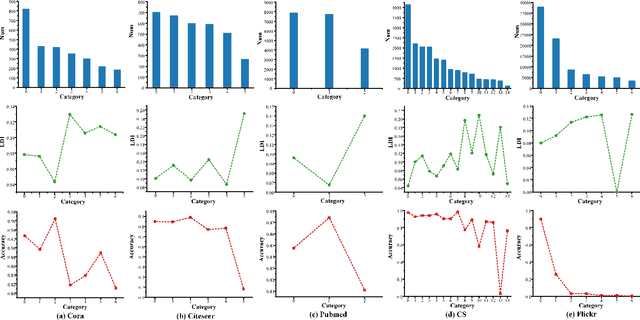
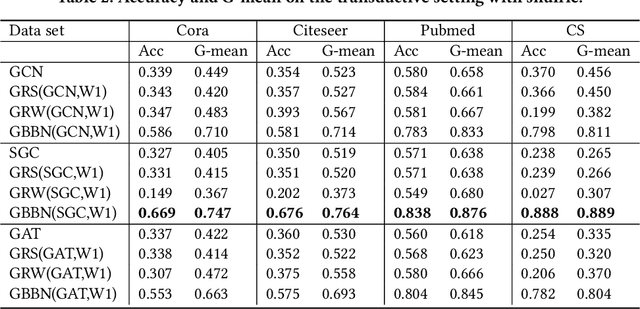
Different from deep neural networks for non-graph data classification, graph neural networks (GNNs) leverage the information exchange between nodes (or samples) when representing nodes. The category distribution shows an imbalance or even a highly-skewed trend on nearly all existing benchmark GNN data sets. The imbalanced distribution will cause misclassification of nodes in the minority classes, and even cause the classification performance on the entire data set to decrease. This study explores the effects of the imbalance problem on the performances of GNNs and proposes new methodologies to solve it. First, a node-level index, namely, the label difference index ($LDI$), is defined to quantitatively analyze the relationship between imbalance and misclassification. The less samples in a class, the higher the value of its average $LDI$; the higher the $LDI$ of a sample, the more likely the sample will be misclassified. We define a new loss and propose four new methods based on $LDI$. Experimental results indicate that the classification accuracies of the three among our proposed four new methods are better in both transductive and inductive settings. The $LDI$ can be applied to other GNNs.