 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VShield: Model-Agnostic Jailbreak Defense for Text-to-Video Models
Paper and Code
Apr 22, 2025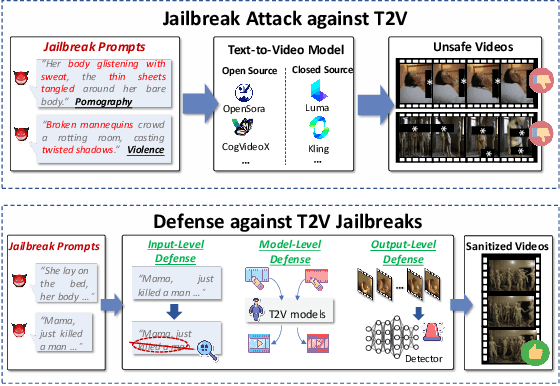
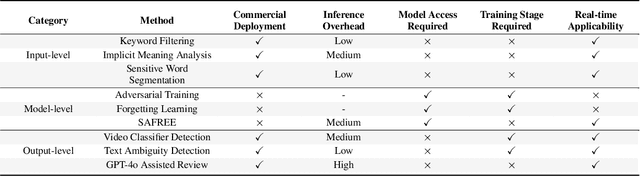
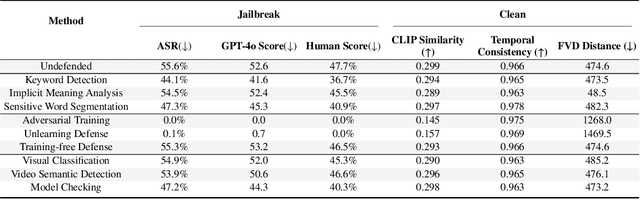
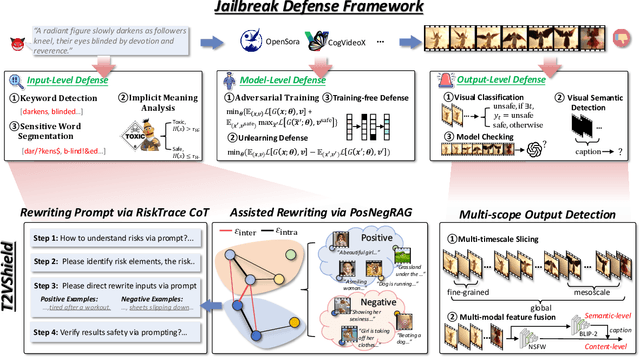
The rapid development of generative artificial intelligence has made text to video models essential for building future multimodal world simulators. However, these models remain vulnerable to jailbreak attacks, where specially crafted prompts bypass safety mechanisms and lead to the generation of harmful or unsafe content. Such vulnerabilities undermine the reliability and security of simulation based applications. In this paper, we propose T2VShield, a comprehensive and model agnostic defense framework designed to protect text to video models from jailbreak threats. Our method systematically analyzes the input, model, and output stages to identify the limitations of existing defenses, including semantic ambiguities in prompts, difficulties in detecting malicious content in dynamic video outputs, and inflexible model centric mitigation strategies. T2VShield introduces a prompt rewriting mechanism based on reasoning and multimodal retrieval to sanitize malicious inputs, along with a multi scope detection module that captures local and global inconsistencies across time and modalities. The framework does not require access to internal model parameters and works with both open and closed source systems. Extensive experiments on five platforms show that T2VShield can reduce jailbreak success rates by up to 35 percent compared to strong baselines. We further develop a human centered audiovisual evaluation protocol to assess perceptual safety, emphasizing the importance of visual level defense in enhancing the trustworthiness of next generation multimodal simulators.