 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Persistence in Language Models: Priming as a Window into Abstract Language Representations
Paper and Code
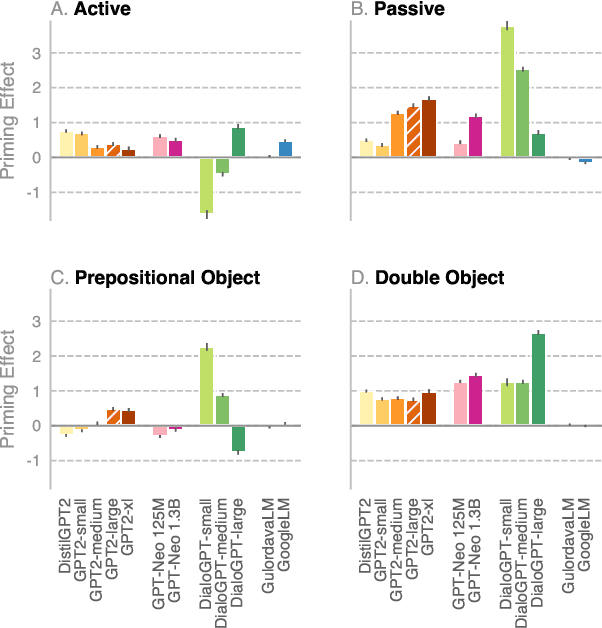
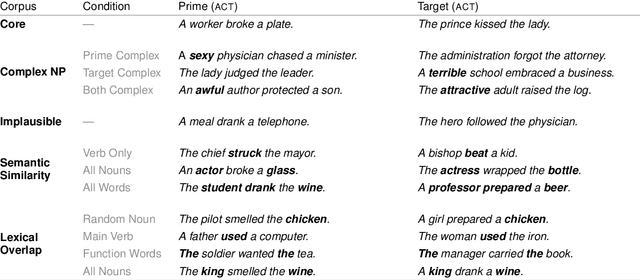
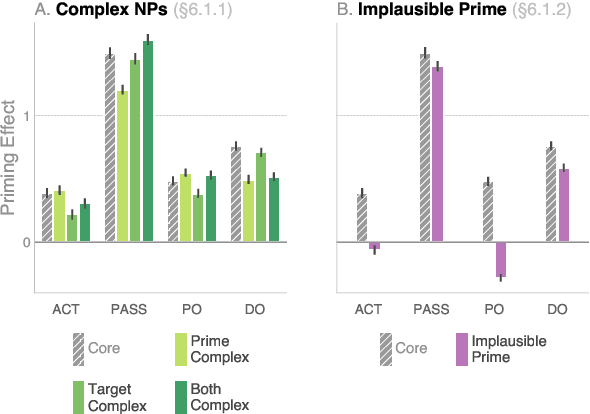
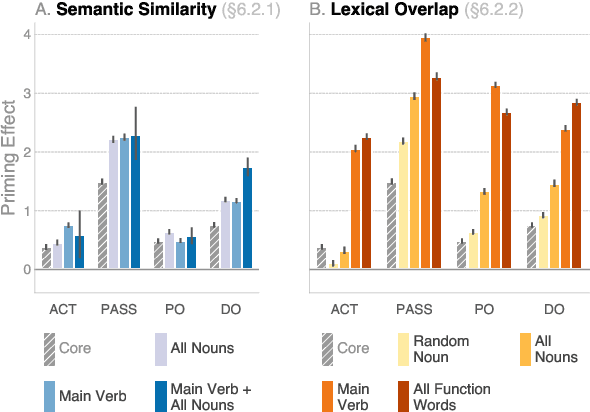
We investigate the extent to which modern, neural language models are susceptible to syntactic priming, the phenomenon where the syntactic structure of a sentence makes the same structure more probable in a follow-up sentence. We explore how priming can be used to study the nature of the syntactic knowledge acquired by these models. We introduce a novel metric and release Prime-LM, a large corpus where we control for various linguistic factors which interact with priming strength. We find that recent large Transformer models indeed show evidence of syntactic priming, but also that the syntactic generalisations learned by these models are to some extent modulated by semantic information. We report surprisingly strong priming effects when priming with multiple sentences, each with different words and meaning but with identical syntactic structure. We conclude that the syntactic priming paradigm is a highly useful, additional tool for gaining insights into the capacities of language models.