 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic and Semantic Features For Code-Switching Factored Language Models
Paper and Code
Oct 04, 2017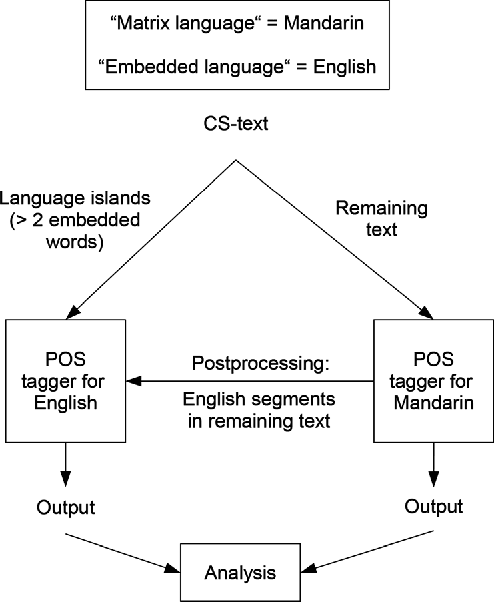
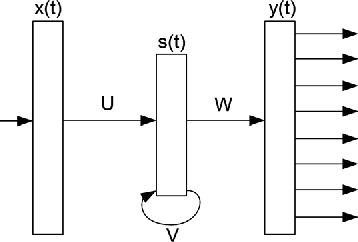
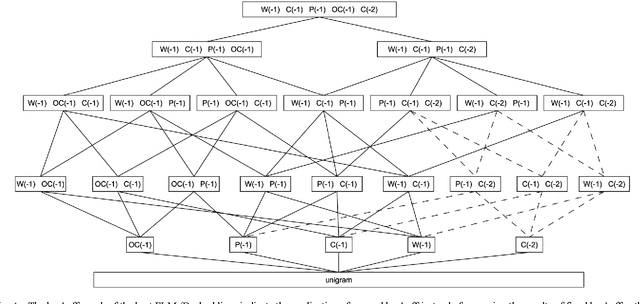
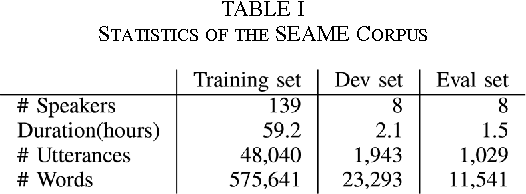
This paper presents our latest investigations on different features for factored language models for Code-Switching speech and their effect on automatic speech recognition (ASR) performance. We focus on syntactic and semantic features which can be extracted from Code-Switching text data and integrate them into factored language models. Different possible factors, such as words, part-of-speech tags, Brown word clusters, open class words and clusters of open class word embeddings are explored. The experimental results reveal that Brown word clusters, part-of-speech tags and open-class words are the most effective at reducing the perplexity of factored language models on the Mandarin-English Code-Switching corpus SEAME. In ASR experiments, the model containing Brown word clusters and part-of-speech tags and the model also including clusters of open class word embeddings yield the best mixed error rate results. In summary, the best language model can significantly reduce the perplexity on the SEAME evaluation set by up to 10.8% relative and the mixed error rate by up to 3.4% relative.