 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwords: A Benchmark for Lexical Substitution with Improved Data Coverage and Quality
Paper and Code

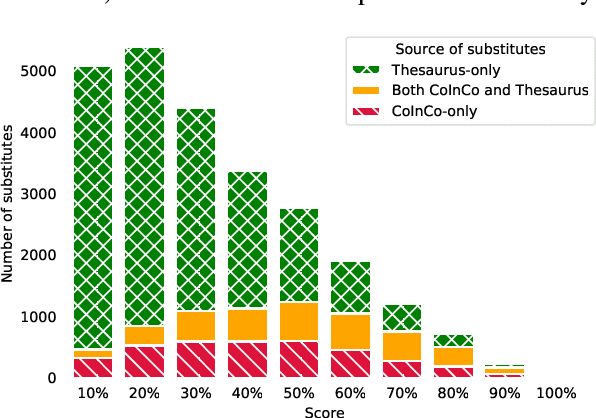
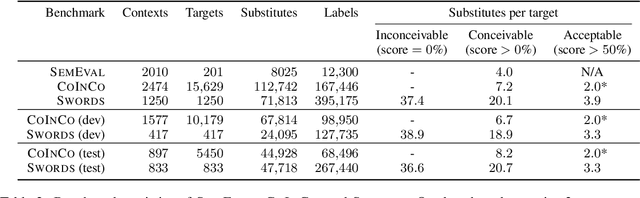
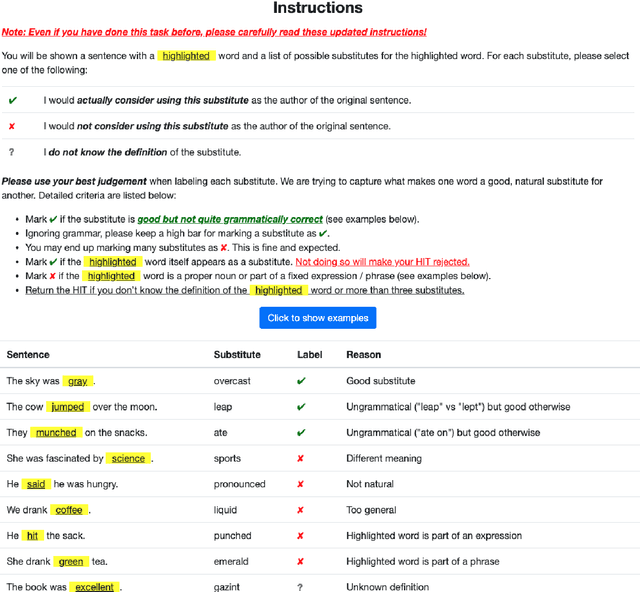
We release a new benchmark for lexical substitution, the task of finding appropriate substitutes for a target word in a context. To assist humans with writing, lexical substitution systems can suggest words that humans cannot easily think of. However, existing benchmarks depend on human recall as the only source of data, and therefore lack coverage of the substitutes that would be most helpful to humans. Furthermore, annotators often provide substitutes of low quality, which are not actually appropriate in the given context. We collect higher-coverage and higher-quality data by framing lexical substitution as a classification problem, guided by the intuition that it is easier for humans to judge the appropriateness of candidate substitutes than conjure them from memory. To this end, we use a context-free thesaurus to produce candidates and rely on human judgement to determine contextual appropriateness. Compared to the previous largest benchmark, our Swords benchmark has 4.1x more substitutes per target word for the same level of quality, and its substitutes are 1.5x more appropriate (based on human judgement) for the same number of substitutes.