 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinCross: Cross-modal Swin Transformer for Head-and-Neck Tumor Segmentation in PET/CT Images
Paper and Code
Feb 08, 2023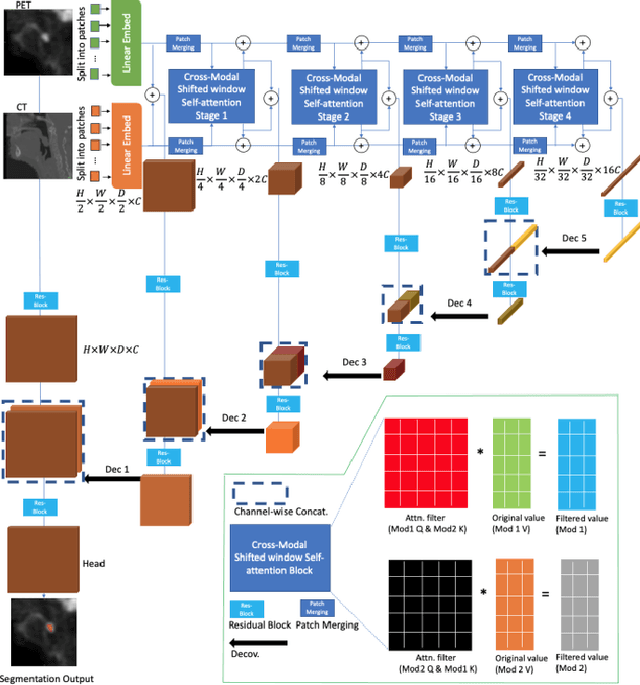
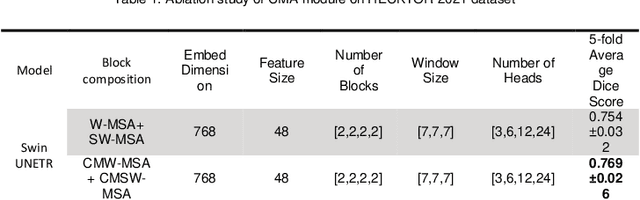
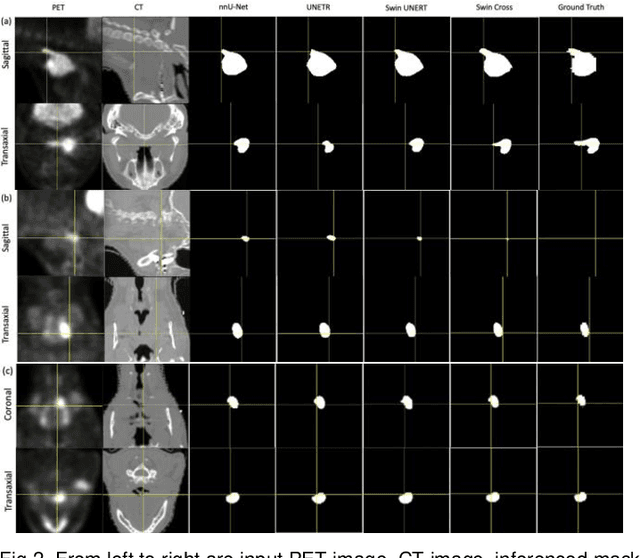
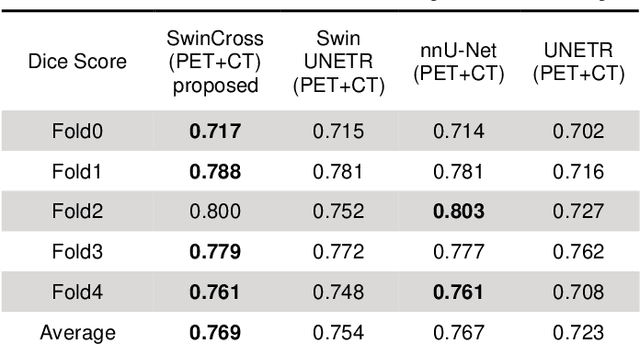
Radiotherapy (RT) combined with cetuximab is the standard treatment for patients with inoperable head and neck cancers. Segmentation of head and neck (H&N) tumors is a prerequisite for radiotherapy planning but a time-consuming process. In recent years, deep convolutional neural networks have become the de facto standard for automated image segmentation. However, due to the expensive computational cost associated with enlarging the field of view in DCNNs, their ability to model long-range dependency is still limited, and this can result in sub-optimal segmentation performance for objects with background context spanning over long distances. On the other hand, Transformer models have demonstrated excellent capabilities in capturing such long-range information in several semantic segmentation tasks performed on medical images. Inspired by the recent success of Vision Transformers and advances in multi-modal image analysis, we propose a novel segmentation model, debuted, Cross-Modal Swin Transformer (SwinCross), with cross-modal attention (CMA) module to incorporate cross-modal feature extraction at multiple resolutions.To validate the effectiveness of the proposed method, we performed experiments on the HECKTOR 2021 challenge dataset and compared it with the nnU-Net (the backbone of the top-5 methods in HECKTOR 2021) and other state-of-the-art transformer-based methods such as UNETR, and Swin UNETR. The proposed method is experimentally shown to outperform these comparing methods thanks to the ability of the CMA module to capture better inter-modality complimentary feature representations between PET and CT, for the task of head-and-neck tumor segmentation.