 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprises in High-Dimensional Ridgeless Least Squares Interpolation
Paper and Code
Apr 02, 2019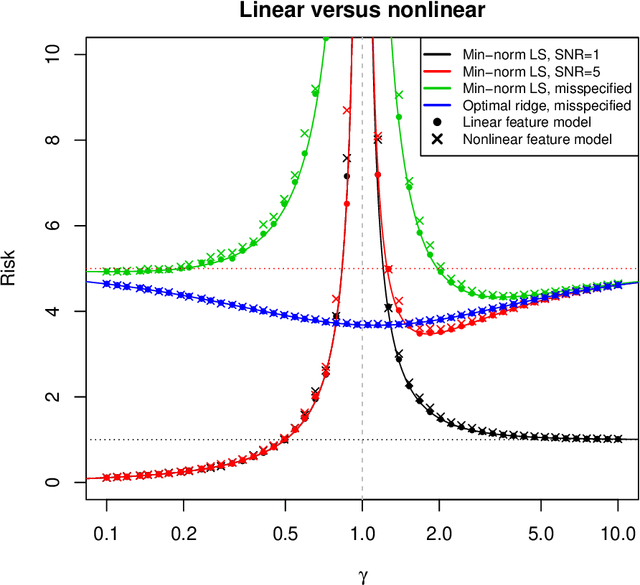
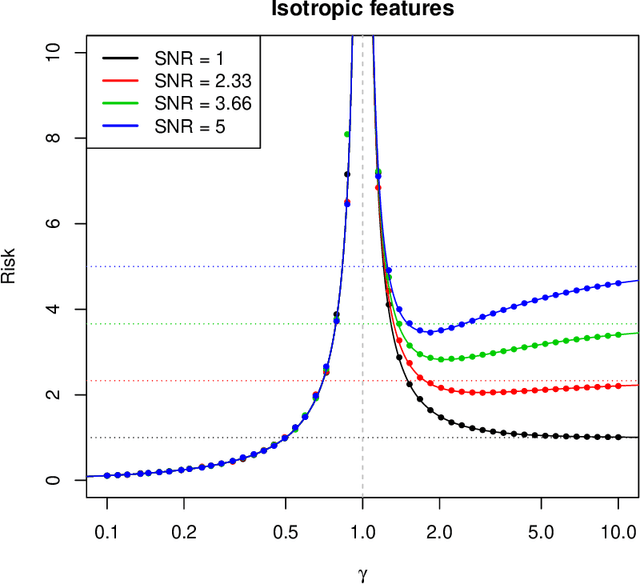
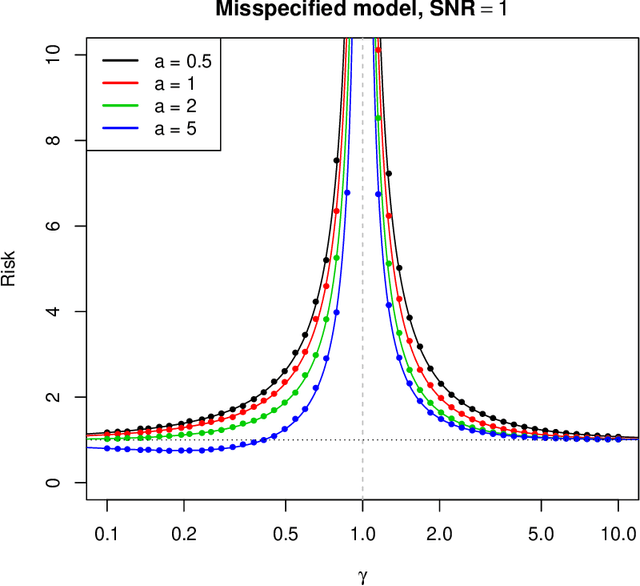

Interpolators---estimators that achieve zero training error---have attracted growing attention in machine learning, mainly because state-of-the art neural networks appear to be models of this type. In this paper, we study minimum $\ell_2$ norm (`ridgeless') interpolation in high-dimensional least squares regression. We consider two different models for the feature distribution: a linear model, where the feature vectors $x_i \in {\mathbb R}^p$ are obtained by applying a linear transform to a vector of i.i.d.\ entries, $x_i = \Sigma^{1/2} z_i$ (with $z_i \in {\mathbb R}^p$); and a nonlinear model, where the feature vectors are obtained by passing the input through a random one-layer neural network, $x_i = \varphi(W z_i)$ (with $z_i \in {\mathbb R}^d$, $W \in {\mathbb R}^{p \times d}$ a matrix of i.i.d.\ entries, and $\varphi$ an activation function acting componentwise on $W z_i$). We recover---in a precise quantitative way---several phenomena that have been observed in large-scale neural networks and kernel machines, including the `double descent' behavior of the prediction risk, and the potential benefits of overparametrization.