 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Visualization for Data Exploration
Paper and Code
Jun 15, 2020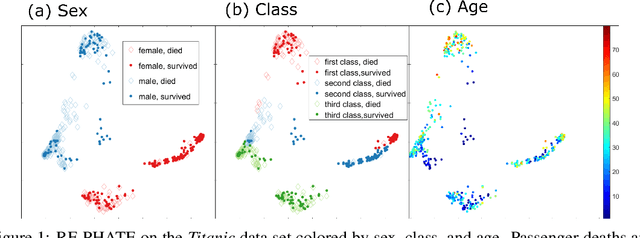
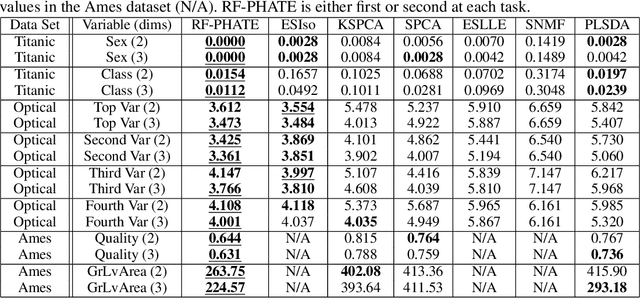
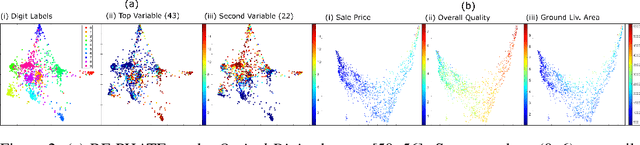
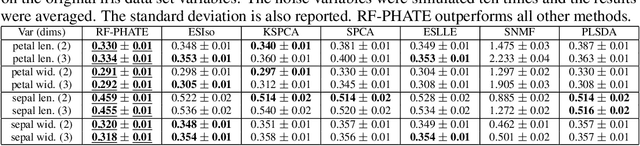
Dimensionality reduction is often used as an initial step in data exploration, either as preprocessing for classification or regression or for visualization. Most dimensionality reduction techniques to date are unsupervised; they do not take class labels into account (e.g., PCA, MDS, t-SNE, Isomap). Such methods require large amounts of data and are often sensitive to noise that may obfuscate important patterns in the data. Various attempts at supervised dimensionality reduction methods that take into account auxiliary annotations (e.g., class labels) have been successfully implemented with goals of increased classification accuracy or improved data visualization. Many of these supervised techniques incorporate labels in the loss function in the form of similarity or dissimilarity matrices, thereby creating over-emphasized separation between class clusters, which does not realistically represent the local and global relationships in the data. In addition, these approaches are often sensitive to parameter tuning, which may be difficult to configure without an explicit quantitative notion of visual superiority. In this paper, we describe a novel supervised visualization technique based on random forest proximities and diffusion-based dimensionality reduction. We show, both qualitatively and quantitatively, the advantages of our approach in retaining local and global structures in data, while emphasizing important variables in the low-dimensional embedding. Importantly, our approach is robust to noise and parameter tuning, thus making it simple to use while producing reliable visualizations for data exploration.