 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Deep Hashing for High-dimensional and Heterogeneous Case-based Reasoning
Paper and Code



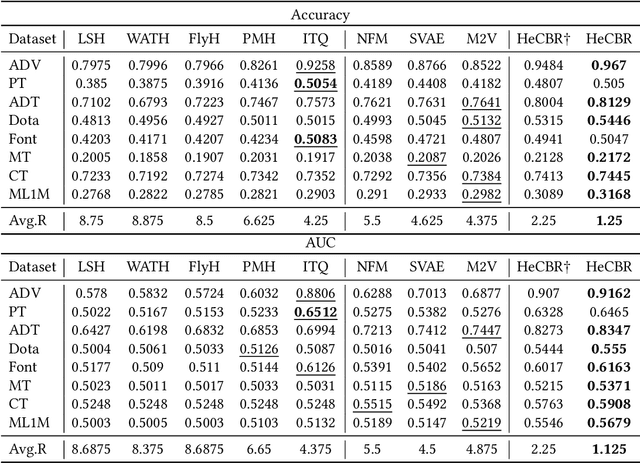
Case-based Reasoning (CBR) on high-dimensional and heterogeneous data is a trending yet challenging and computationally expensive task in the real world. A promising approach is to obtain low-dimensional hash codes representing cases and perform a similarity retrieval of cases in Hamming space. However, previous methods based on data-independent hashing rely on random projections or manual construction, inapplicable to address specific data issues (e.g., high-dimensionality and heterogeneity) due to their insensitivity to data characteristics. To address these issues, this work introduces a novel deep hashing network to learn similarity-preserving compact hash codes for efficient case retrieval and proposes a deep-hashing-enabled CBR model HeCBR. Specifically, we introduce position embedding to represent heterogeneous features and utilize a multilinear interaction layer to obtain case embeddings, which effectively filtrates zero-valued features to tackle high-dimensionality and sparsity and captures inter-feature couplings. Then, we feed the case embeddings into fully-connected layers, and subsequently a hash layer generates hash codes with a quantization regularizer to control the quantization loss during relaxation. To cater to incremental learning of CBR, we further propose an adaptive learning strategy to update the hash function. Extensive experiments on public datasets show that HeCBR greatly reduces storage and significantly accelerates case retrieval. HeCBR achieves desirable performance compared with the state-of-the-art CBR methods and performs significantly better than hashing-based CBR methods in classification.