 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpolynomial Lower Bounds for Learning One-Layer Neural Networks using Gradient Descent
Paper and Code
Jun 22, 2020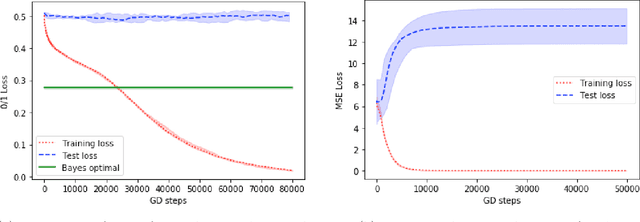

We prove the first superpolynomial lower bounds for learning one-layer neural networks with respect to the Gaussian distribution using gradient descent. We show that any classifier trained using gradient descent with respect to square-loss will fail to achieve small test error in polynomial time given access to samples labeled by a one-layer neural network. For classification, we give a stronger result, namely that any statistical query (SQ) algorithm (including gradient descent) will fail to achieve small test error in polynomial time. Prior work held only for gradient descent run with small batch sizes, required sharp activations, and applied to specific classes of queries. Our lower bounds hold for broad classes of activations including ReLU and sigmoid. The core of our result relies on a novel construction of a simple family of neural networks that are exactly orthogonal with respect to all spherically symmetric distributions.