 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummScore: A Comprehensive Evaluation Metric for Summary Quality Based on Cross-Encoder
Paper and Code
Jul 11, 2022
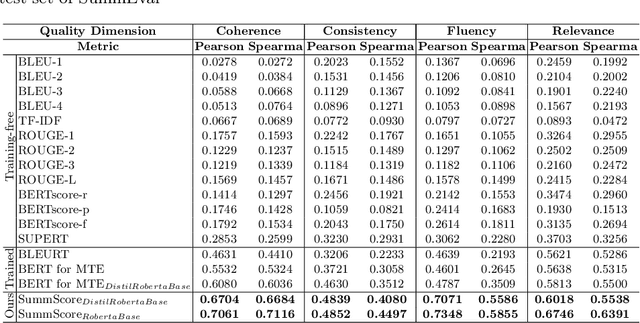

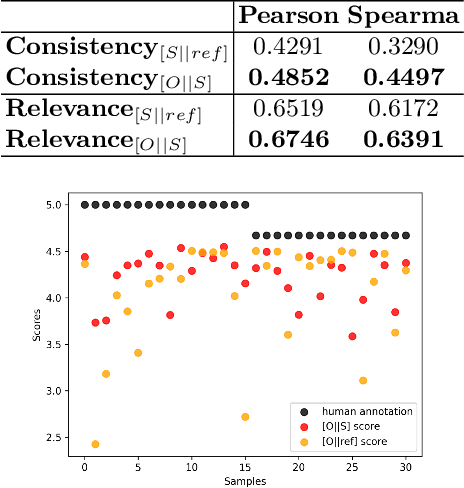
Text summarization models are often trained to produce summaries that meet human quality requirements. However, the existing evaluation metrics for summary text are only rough proxies for summary quality, suffering from low correlation with human scoring and inhibition of summary diversity. To solve these problems, we propose SummScore, a comprehensive metric for summary quality evaluation based on CrossEncoder. Firstly, by adopting the original-summary measurement mode and comparing the semantics of the original text, SummScore gets rid of the inhibition of summary diversity. With the help of the text-matching pre-training Cross-Encoder, SummScore can effectively capture the subtle differences between the semantics of summaries. Secondly, to improve the comprehensiveness and interpretability, SummScore consists of four fine-grained submodels, which measure Coherence, Consistency, Fluency, and Relevance separately. We use semi-supervised multi-rounds of training to improve the performance of our model on extremely limited annotated data. Extensive experiments show that SummScore significantly outperforms existing evaluation metrics in the above four dimensions in correlation with human scoring. We also provide the quality evaluation results of SummScore on 16 mainstream summarization models for later research.