Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSublinear Regret for Learning POMDPs
Paper and Code
Jul 14, 2021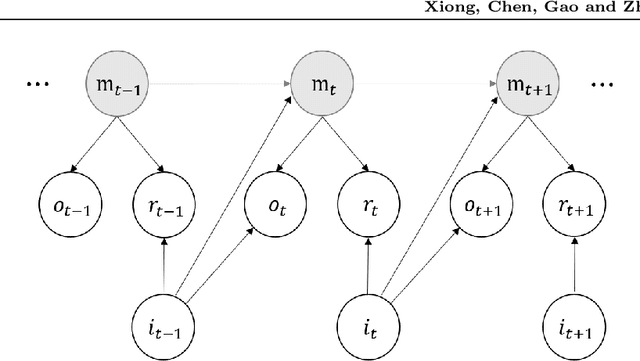
We study the model-based undiscounted reinforcement learning for partially observable Markov decision processes (POMDPs). The oracle we consider is the optimal policy of the POMDP with a known environment in terms of the average reward over an infinite horizon. We propose a learning algorithm for this problem, building on spectral method-of-moments estimations for hidden Markov models, the belief error control in POMDPs and upper-confidence-bound methods for online learning. We establish a regret bound of $O(T^{2/3}\sqrt{\log T})$ for the proposed learning algorithm where $T$ is the learning horizon. This is, to the best of our knowledge, the first algorithm achieving sublinear regret with respect to our oracle for learning general POMDPs.
View paper on