 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Variance-Reduced Policy Gradient
Paper and Code
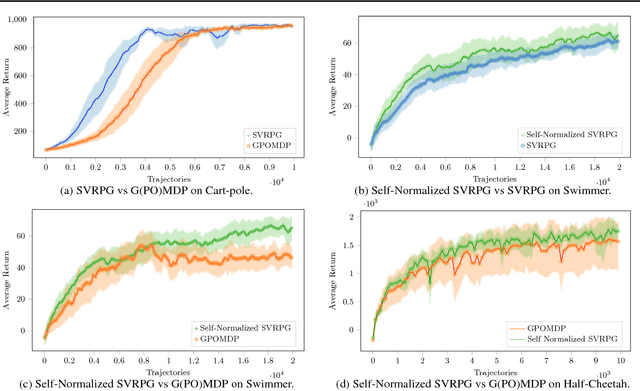
In this paper, we propose a novel reinforcement- learning algorithm consisting in a stochastic variance-reduced version of policy gradient for solving Markov Decision Processes (MDPs). Stochastic variance-reduced gradient (SVRG) methods have proven to be very successful in supervised learning. However, their adaptation to policy gradient is not straightforward and needs to account for I) a non-concave objective func- tion; II) approximations in the full gradient com- putation; and III) a non-stationary sampling pro- cess. The result is SVRPG, a stochastic variance- reduced policy gradient algorithm that leverages on importance weights to preserve the unbiased- ness of the gradient estimate. Under standard as- sumptions on the MDP, we provide convergence guarantees for SVRPG with a convergence rate that is linear under increasing batch sizes. Finally, we suggest practical variants of SVRPG, and we empirically evaluate them on continuous MDPs.