 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators
Paper and Code
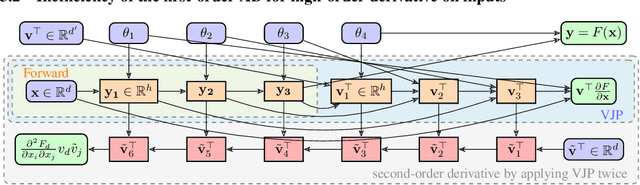
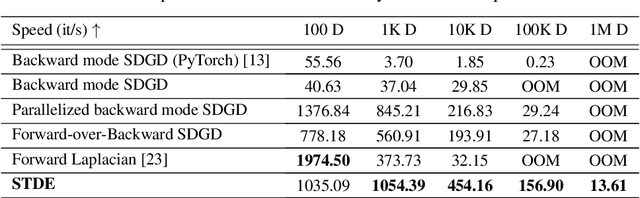

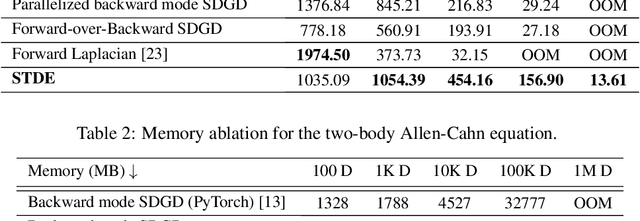
Optimizing neural networks with loss that contain high-dimensional and high-order differential operators is expensive to evaluate with back-propagation due to $\mathcal{O}(d^{k})$ scaling of the derivative tensor size and the $\mathcal{O}(2^{k-1}L)$ scaling in the computation graph, where $d$ is the dimension of the domain, $L$ is the number of ops in the forward computation graph, and $k$ is the derivative order. In previous works, the polynomial scaling in $d$ was addressed by amortizing the computation over the optimization process via randomization. Separately, the exponential scaling in $k$ for univariate functions ($d=1$) was addressed with high-order auto-differentiation (AD). In this work, we show how to efficiently perform arbitrary contraction of the derivative tensor of arbitrary order for multivariate functions, by properly constructing the input tangents to univariate high-order AD, which can be used to efficiently randomize any differential operator. When applied to Physics-Informed Neural Networks (PINNs), our method provides >1000$\times$ speed-up and >30$\times$ memory reduction over randomization with first-order AD, and we can now solve \emph{1-million-dimensional PDEs in 8 minutes on a single NVIDIA A100 GPU}. This work opens the possibility of using high-order differential operators in large-scale problems.