 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic gradient descent for hybrid quantum-classical optimization
Paper and Code
Oct 02, 2019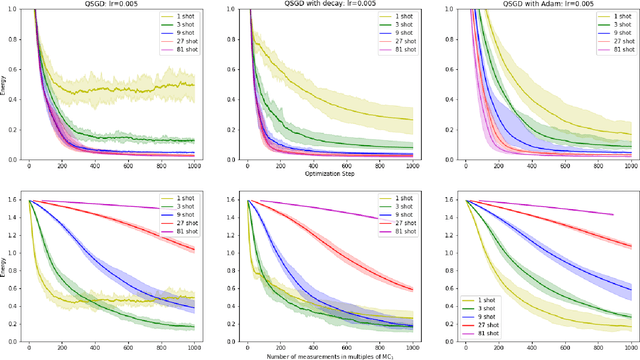
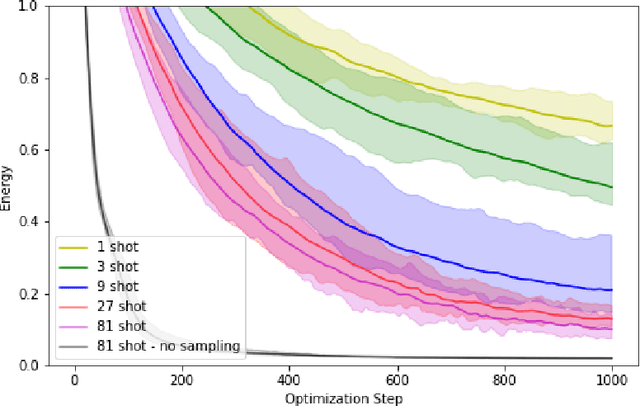
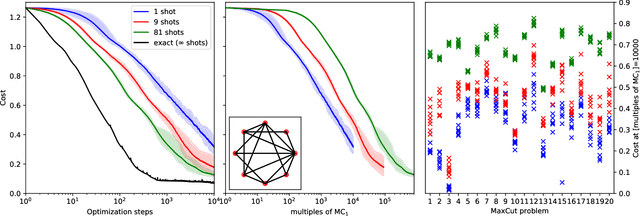
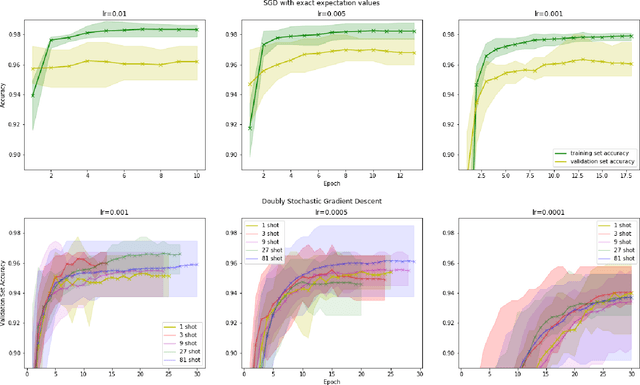
Within the context of hybrid quantum-classical optimization, gradient descent based optimizers typically require the evaluation of expectation values with respect to the outcome of parameterized quantum circuits. In this work, we explore the significant consequences of the simple observation that the estimation of these quantities on quantum hardware is a form of stochastic gradient descent optimization. We formalize this notion, which allows us to show that in many relevant cases, including VQE, QAOA and certain quantum classifiers, estimating expectation values with $k$ measurement outcomes results in optimization algorithms whose convergence properties can be rigorously well understood, for any value of $k$. In fact, even using single measurement outcomes for the estimation of expectation values is sufficient. Moreover, in many settings the required gradients can be expressed as linear combinations of expectation values -- originating, e.g., from a sum over local terms of a Hamiltonian, a parameter shift rule, or a sum over data-set instances -- and we show that in these cases $k$-shot expectation value estimation can be combined with sampling over terms of the linear combination, to obtain "doubly stochastic" gradient descent optimizers. For all algorithms we prove convergence guarantees, providing a framework for the derivation of rigorous optimization results in the context of near-term quantum devices. Additionally, we explore numerically these methods on benchmark VQE, QAOA and quantum-enhanced machine learning tasks and show that treating the stochastic settings as hyper-parameters allows for state-of-the-art results with significantly fewer circuit executions and measurements.