 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Matching by Self-supervision of Multiscopic Vision
Paper and Code
Apr 09, 2021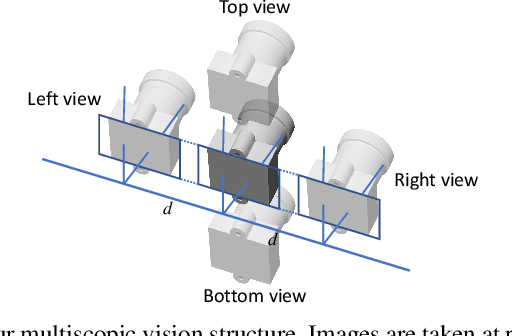

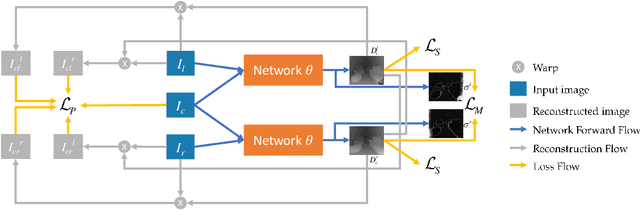

Self-supervised learning for depth estimation possesses several advantages over supervised learning. The benefits of no need for ground-truth depth, online fine-tuning, and better generalization with unlimited data attract researchers to seek self-supervised solutions. In this work, we propose a new self-supervised framework for stereo matching utilizing multiple images captured at aligned camera positions. A cross photometric loss, an uncertainty-aware mutual-supervision loss, and a new smoothness loss are introduced to optimize the network in learning disparity maps end-to-end without ground-truth depth information. To train this framework, we build a new multiscopic dataset consisting of synthetic images rendered by 3D engines and real images captured by real cameras. After being trained with only the synthetic images, our network can perform well in unseen outdoor scenes. Our experiment shows that our model obtains better disparity maps than previous unsupervised methods on the KITTI dataset and is comparable to supervised methods when generalized to unseen data. Our source code and dataset will be made public, and more results are provided in the supplement.