 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-by-step Erasion, One-by-one Collection: A Weakly Supervised Temporal Action Detector
Paper and Code
Jul 18, 2018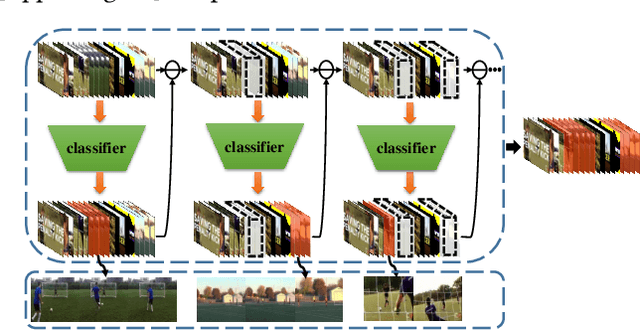

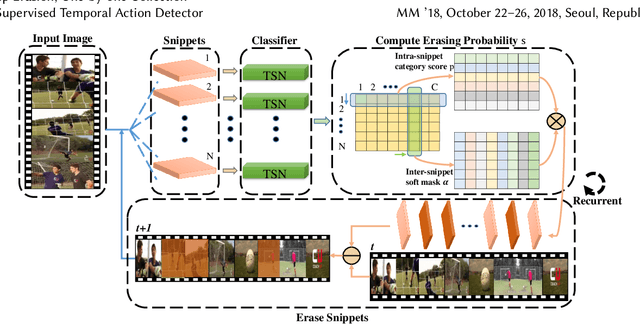
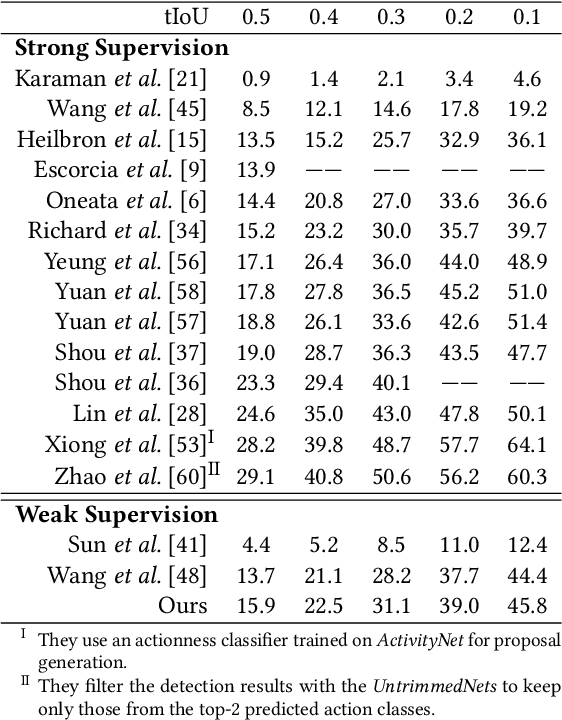
Weakly supervised temporal action detection is a Herculean task in understanding untrimmed videos, since no supervisory signal except the video-level category label is available on training data. Under the supervision of category labels, weakly supervised detectors are usually built upon classifiers. However, there is an inherent contradiction between classifier and detector; i.e., a classifier in pursuit of high classification performance prefers top-level discriminative video clips that are extremely fragmentary, whereas a detector is obliged to discover the whole action instance without missing any relevant snippet. To reconcile this contradiction, we train a detector by driving a series of classifiers to find new actionness clips progressively, via step-by-step erasion from a complete video. During the test phase, all we need to do is to collect detection results from the one-by-one trained classifiers at various erasing steps. To assist in the collection process, a fully connected conditional random field is established to refine the temporal localization outputs. We evaluate our approach on two prevailing datasets, THUMOS'14 and ActivityNet. The experiments show that our detector advances state-of-the-art weakly supervised temporal action detection results, and even compares with quite a few strongly supervised methods.