 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackelberg GAN: Towards Provable Minimax Equilibrium via Multi-Generator Architectures
Paper and Code
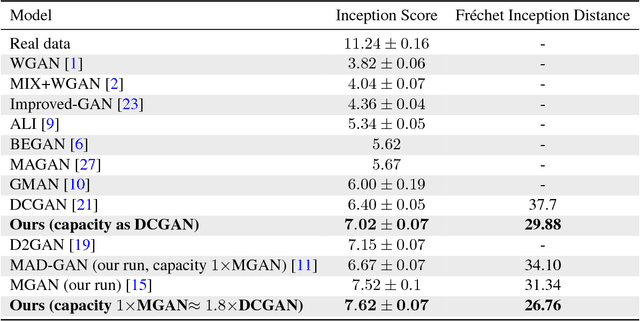
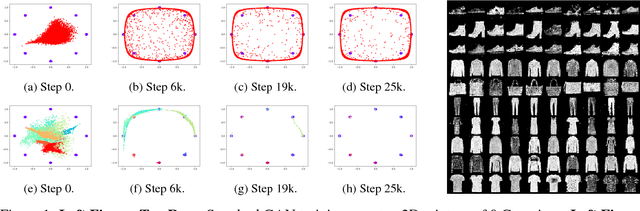
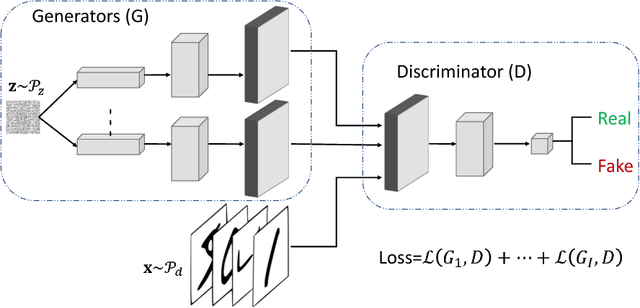
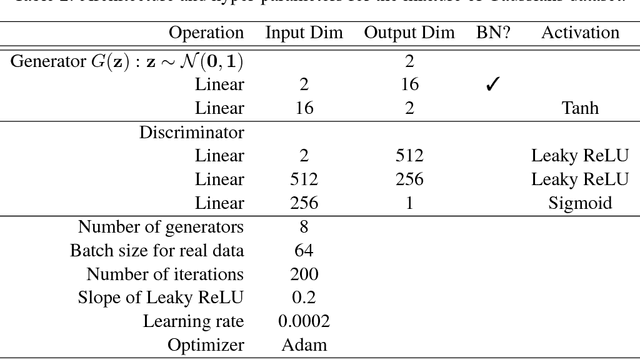
We study the problem of alleviating the instability issue in the GAN training procedure via new architecture design. The discrepancy between the minimax and maximin objective values could serve as a proxy for the difficulties that the alternating gradient descent encounters in the optimization of GANs. In this work, we give new results on the benefits of multi-generator architecture of GANs. We show that the minimax gap shrinks to $\epsilon$ as the number of generators increases with rate $\widetilde{O}(1/\epsilon)$. This improves over the best-known result of $\widetilde{O}(1/\epsilon^2)$. At the core of our techniques is a novel application of Shapley-Folkman lemma to the generic minimax problem, where in the literature the technique was only known to work when the objective function is restricted to the Lagrangian function of a constraint optimization problem. Our proposed Stackelberg GAN performs well experimentally in both synthetic and real-world datasets, improving Fr\'echet Inception Distance by $14.61\%$ over the previous multi-generator GANs on the benchmark datasets.