 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSquared $\ell_2$ Norm as Consistency Loss for Leveraging Augmented Data to Learn Robust and Invariant Representations
Paper and Code
Nov 25, 2020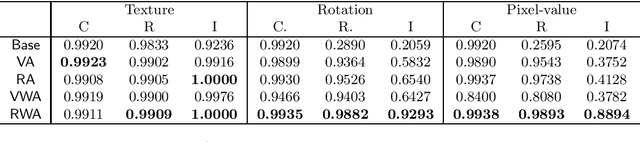



Data augmentation is one of the most popular techniques for improving the robustness of neural networks. In addition to directly training the model with original samples and augmented samples, a torrent of methods regularizing the distance between embeddings/representations of the original samples and their augmented counterparts have been introduced. In this paper, we explore these various regularization choices, seeking to provide a general understanding of how we should regularize the embeddings. Our analysis suggests the ideal choices of regularization correspond to various assumptions. With an invariance test, we argue that regularization is important if the model is to be used in a broader context than the accuracy-driven setting because non-regularized approaches are limited in learning the concept of invariance, despite equally high accuracy. Finally, we also show that the generic approach we identified (squared $\ell_2$ norm regularized augmentation) outperforms several recent methods, which are each specially designed for one task and significantly more complicated than ours, over three different tasks.