 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotlight Text Detector: Spotlight on Candidate Regions Like a Camera
Paper and Code
Sep 25, 2024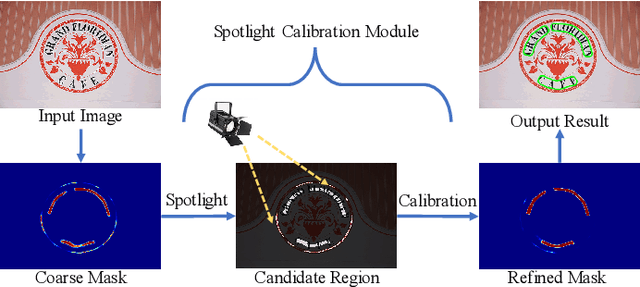
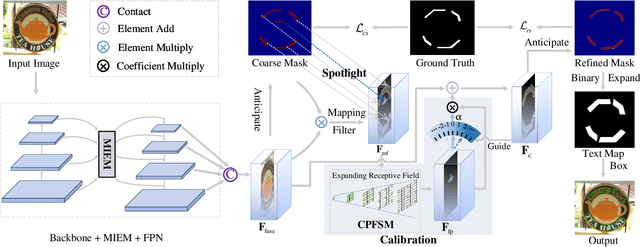


The irregular contour representation is one of the tough challenges in scene text detection. Although segmentation-based methods have achieved significant progress with the help of flexible pixel prediction, the overlap of geographically close texts hinders detecting them separately. To alleviate this problem, some shrink-based methods predict text kernels and expand them to restructure texts. However, the text kernel is an artificial object with incomplete semantic features that are prone to incorrect or missing detection. In addition, different from the general objects, the geometry features (aspect ratio, scale, and shape) of scene texts vary significantly, which makes it difficult to detect them accurately. To consider the above problems, we propose an effective spotlight text detector (STD), which consists of a spotlight calibration module (SCM) and a multivariate information extraction module (MIEM). The former concentrates efforts on the candidate kernel, like a camera focus on the target. It obtains candidate features through a mapping filter and calibrates them precisely to eliminate some false positive samples. The latter designs different shape schemes to explore multiple geometric features for scene texts. It helps extract various spatial relationships to improve the model's ability to recognize kernel regions. Ablation studies prove the effectiveness of the designed SCM and MIEM. Extensive experiments verify that our STD is superior to existing state-of-the-art methods on various datasets, including ICDAR2015, CTW1500, MSRA-TD500, and Total-Text.