 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLDExtraTrees: Robust machine learning approach for predicting kinase inhibitor resistance
Paper and Code
Nov 25, 2021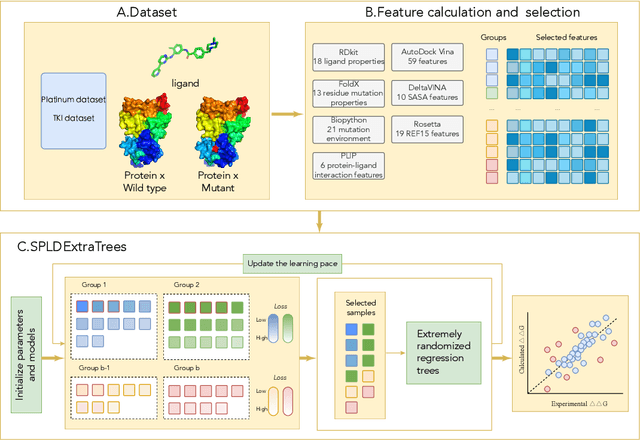
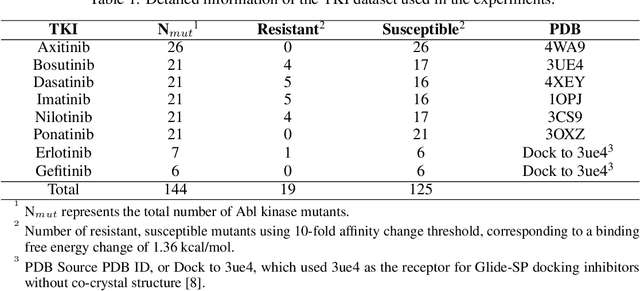
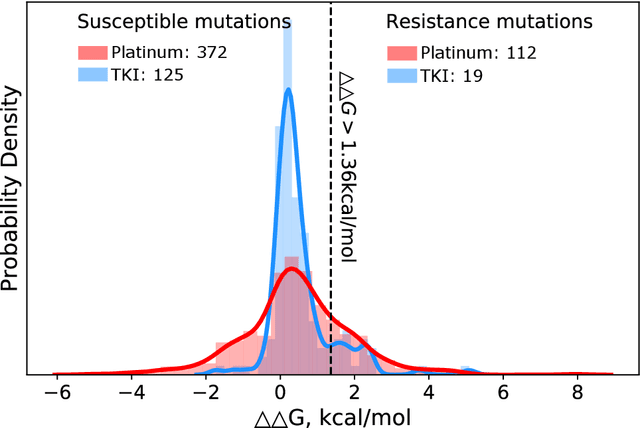
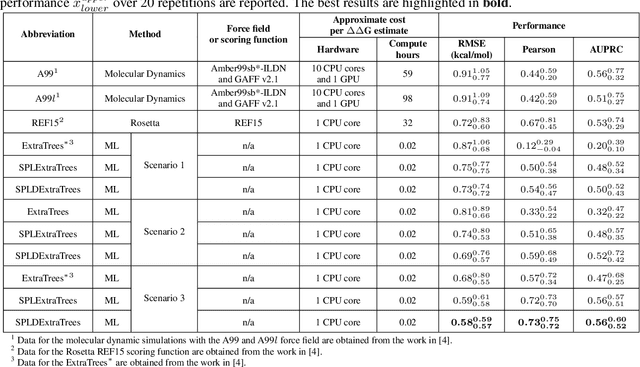
Drug resistance is a major threat to the global health and a significant concern throughout the clinical treatment of diseases and drug development. The mutation in proteins that is related to drug binding is a common cause for adaptive drug resistance. Therefore, quantitative estimations of how mutations would affect the interaction between a drug and the target protein would be of vital significance for the drug development and the clinical practice. Computational methods that rely on molecular dynamics simulations, Rosetta protocols, as well as machine learning methods have been proven to be capable of predicting ligand affinity changes upon protein mutation. However, the severely limited sample size and heavy noise induced overfitting and generalization issues have impeded wide adoption of machine learning for studying drug resistance. In this paper, we propose a robust machine learning method, termed SPLDExtraTrees, which can accurately predict ligand binding affinity changes upon protein mutation and identify resistance-causing mutations. Especially, the proposed method ranks training data following a specific scheme that starts with easy-to-learn samples and gradually incorporates harder and diverse samples into the training, and then iterates between sample weight recalculations and model updates. In addition, we calculate additional physics-based structural features to provide the machine learning model with the valuable domain knowledge on proteins for this data-limited predictive tasks. The experiments substantiate the capability of the proposed method for predicting kinase inhibitor resistance under three scenarios, and achieves predictive accuracy comparable to that of molecular dynamics and Rosetta methods with much less computational costs.