Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeeding up Deep Model Training by Sharing Weights and Then Unsharing
Paper and Code
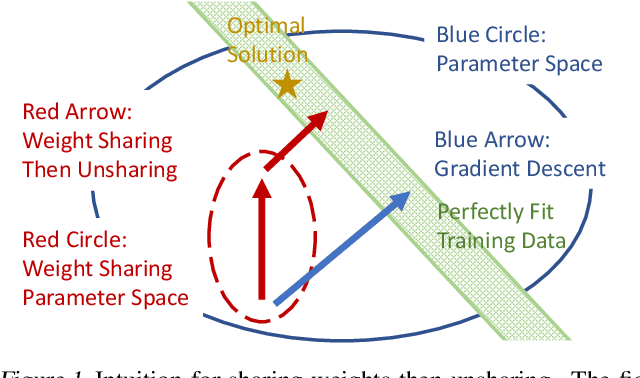
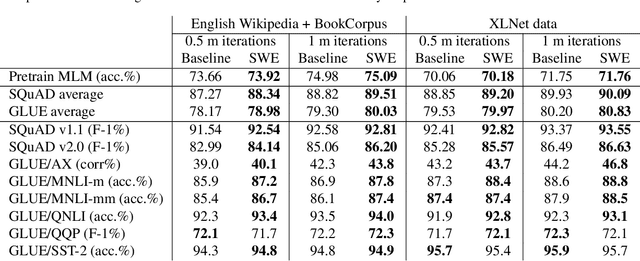
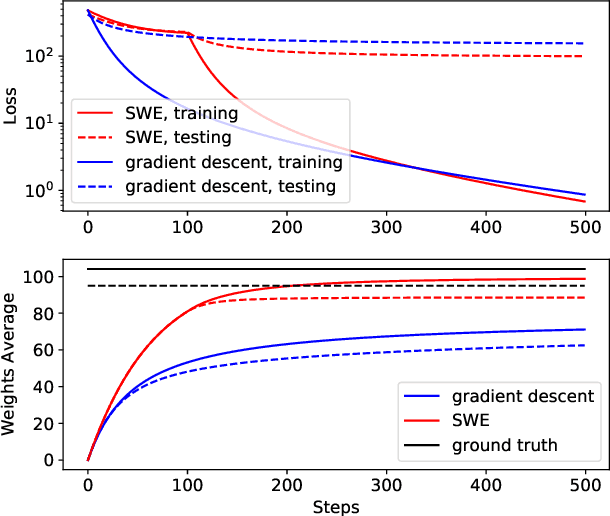
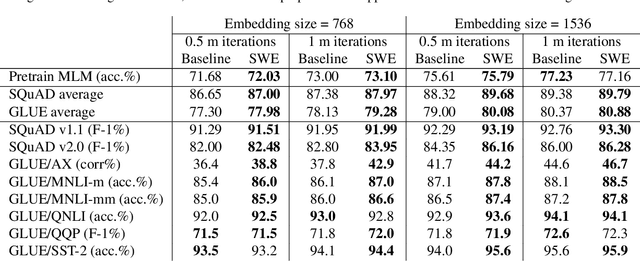
We propose a simple and efficient approach for training the BERT model. Our approach exploits the special structure of BERT that contains a stack of repeated modules (i.e., transformer encoders). Our proposed approach first trains BERT with the weights shared across all the repeated modules till some point. This is for learning the commonly shared component of weights across all repeated layers. We then stop weight sharing and continue training until convergence. We present theoretic insights for training by sharing weights then unsharing with analysis for simplified models. Empirical experiments on the BERT model show that our method yields better performance of trained models, and significantly reduces the number of training iterations.
View paper on