 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecial Characters Attack: Toward Scalable Training Data Extraction From Large Language Models
Paper and Code

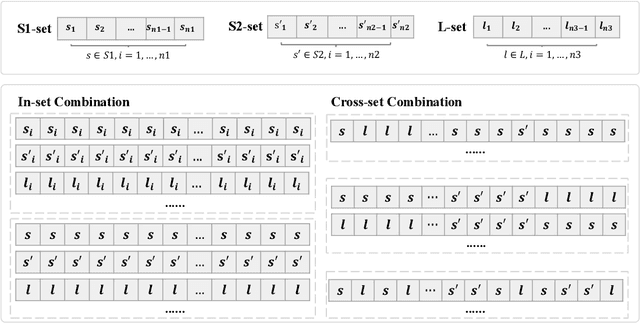

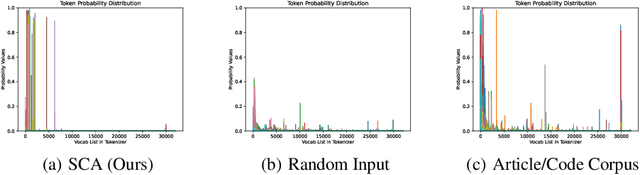
Large language models (LLMs) have achieved remarkable performance on a wide range of tasks. However, recent studies have shown that LLMs can memorize training data and simple repeated tokens can trick the model to leak the data. In this paper, we take a step further and show that certain special characters or their combinations with English letters are stronger memory triggers, leading to more severe data leakage. The intuition is that, since LLMs are trained with massive data that contains a substantial amount of special characters (e.g. structural symbols {, } of JSON files, and @, # in emails and online posts), the model may memorize the co-occurrence between these special characters and the raw texts. This motivates us to propose a simple but effective Special Characters Attack (SCA) to induce training data leakage. Our experiments verify the high effectiveness of SCA against state-of-the-art LLMs: they can leak diverse training data, such as code corpus, web pages, and personally identifiable information, and sometimes generate non-stop outputs as a byproduct. We further show that the composition of the training data corpus can be revealed by inspecting the leaked data -- one crucial piece of information for pre-training high-performance LLMs. Our work can help understand the sensitivity of LLMs to special characters and identify potential areas for improvement.