 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseFed: Mitigating Model Poisoning Attacks in Federated Learning with Sparsification
Paper and Code

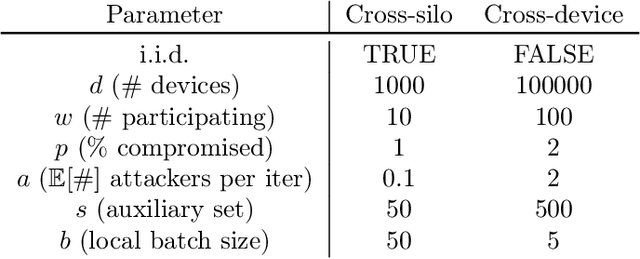


Federated learning is inherently vulnerable to model poisoning attacks because its decentralized nature allows attackers to participate with compromised devices. In model poisoning attacks, the attacker reduces the model's performance on targeted sub-tasks (e.g. classifying planes as birds) by uploading "poisoned" updates. In this report we introduce \algoname{}, a novel defense that uses global top-k update sparsification and device-level gradient clipping to mitigate model poisoning attacks. We propose a theoretical framework for analyzing the robustness of defenses against poisoning attacks, and provide robustness and convergence analysis of our algorithm. To validate its empirical efficacy we conduct an open-source evaluation at scale across multiple benchmark datasets for computer vision and federated learning.