 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse in Space and Time: Audio-visual Synchronisation with Trainable Selectors
Paper and Code
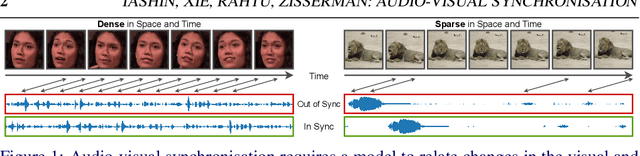

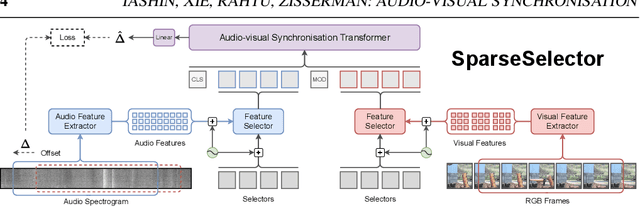
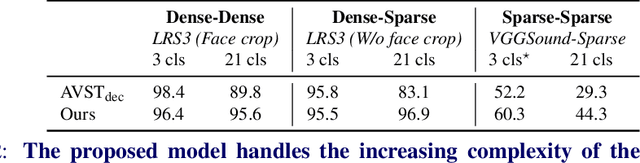
The objective of this paper is audio-visual synchronisation of general videos 'in the wild'. For such videos, the events that may be harnessed for synchronisation cues may be spatially small and may occur only infrequently during a many seconds-long video clip, i.e. the synchronisation signal is 'sparse in space and time'. This contrasts with the case of synchronising videos of talking heads, where audio-visual correspondence is dense in both time and space. We make four contributions: (i) in order to handle longer temporal sequences required for sparse synchronisation signals, we design a multi-modal transformer model that employs 'selectors' to distil the long audio and visual streams into small sequences that are then used to predict the temporal offset between streams. (ii) We identify artefacts that can arise from the compression codecs used for audio and video and can be used by audio-visual models in training to artificially solve the synchronisation task. (iii) We curate a dataset with only sparse in time and space synchronisation signals; and (iv) the effectiveness of the proposed model is shown on both dense and sparse datasets quantitatively and qualitatively. Project page: v-iashin.github.io/SparseSync