 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Fusion Mixture-of-Experts are Domain Generalizable Learners
Paper and Code
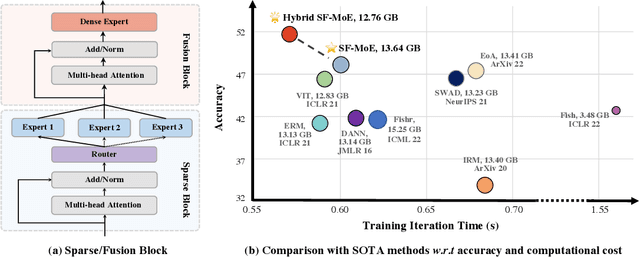
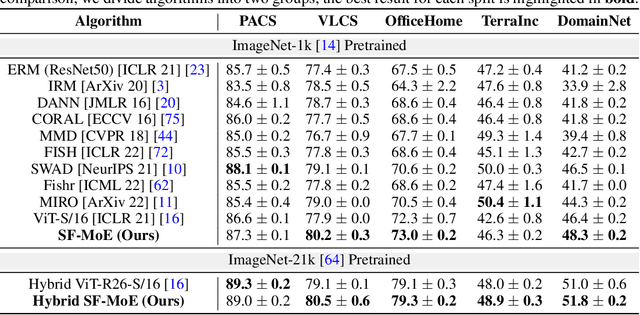
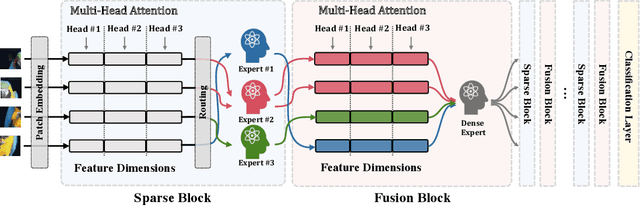
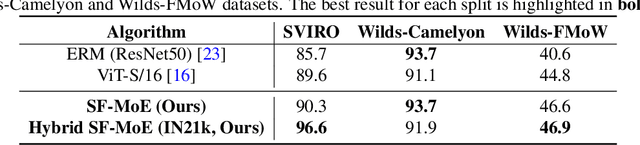
Domain generalization (DG) aims at learning generalizable models under distribution shifts to avoid redundantly overfitting massive training data. Previous works with complex loss design and gradient constraint have not yet led to empirical success on large-scale benchmarks. In this work, we reveal the mixture-of-experts (MoE) model's generalizability on DG by leveraging to distributively handle multiple aspects of the predictive features across domains. To this end, we propose Sparse Fusion Mixture-of-Experts (SF-MoE), which incorporates sparsity and fusion mechanisms into the MoE framework to keep the model both sparse and predictive. SF-MoE has two dedicated modules: 1) sparse block and 2) fusion block, which disentangle and aggregate the diverse learned signals of an object, respectively. Extensive experiments demonstrate that SF-MoE is a domain-generalizable learner on large-scale benchmarks. It outperforms state-of-the-art counterparts by more than 2% across 5 large-scale DG datasets (e.g., DomainNet), with the same or even lower computational costs. We further reveal the internal mechanism of SF-MoE from distributed representation perspective (e.g., visual attributes). We hope this framework could facilitate future research to push generalizable object recognition to the real world. Code and models are released at https://github.com/Luodian/SF-MoE-DG.