 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpacecraft depth completion based on the gray image and the sparse depth map
Paper and Code
Aug 30, 2022
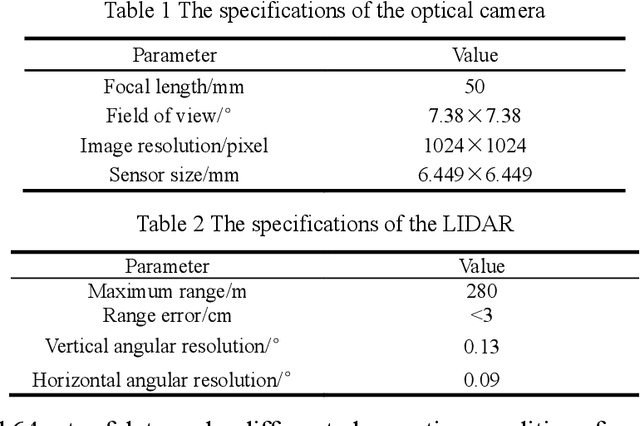
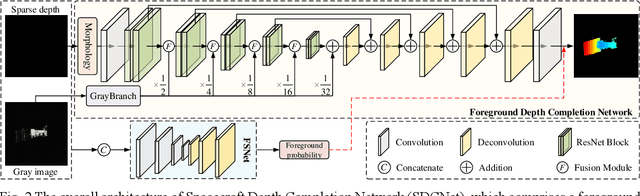
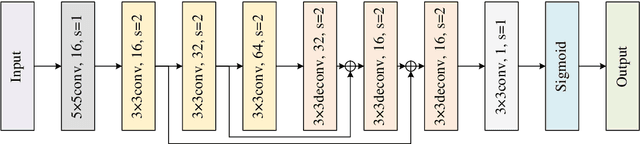
Perceiving the three-dimensional (3D) structure of the spacecraft is a prerequisite for successfully executing many on-orbit space missions, and it can provide critical input for many downstream vision algorithms. In this paper, we propose to sense the 3D structure of spacecraft using light detection and ranging sensor (LIDAR) and a monocular camera. To this end, Spacecraft Depth Completion Network (SDCNet) is proposed to recover the dense depth map based on gray image and sparse depth map. Specifically, SDCNet decomposes the object-level spacecraft depth completion task into foreground segmentation subtask and foreground depth completion subtask, which segments the spacecraft region first and then performs depth completion on the segmented foreground area. In this way, the background interference to foreground spacecraft depth completion is effectively avoided. Moreover, an attention-based feature fusion module is also proposed to aggregate the complementary information between different inputs, which deduces the correlation between different features along the channel and the spatial dimension sequentially. Besides, four metrics are also proposed to evaluate object-level depth completion performance, which can more intuitively reflect the quality of spacecraft depth completion results. Finally, a large-scale satellite depth completion dataset is constructed for training and testing spacecraft depth completion algorithms. Empirical experiments on the dataset demonstrate the effectiveness of the proposed SDCNet, which achieves 0.25m mean absolute error of interest and 0.759m mean absolute truncation error, surpassing state-of-the-art methods by a large margin. The spacecraft pose estimation experiment is also conducted based on the depth completion results, and the experimental results indicate that the predicted dense depth map could meet the needs of downstream vision tasks.