 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMS: An Efficient Source Model Selection Framework for Model Reuse
Paper and Code
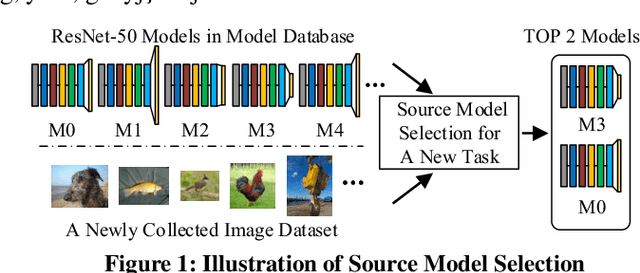
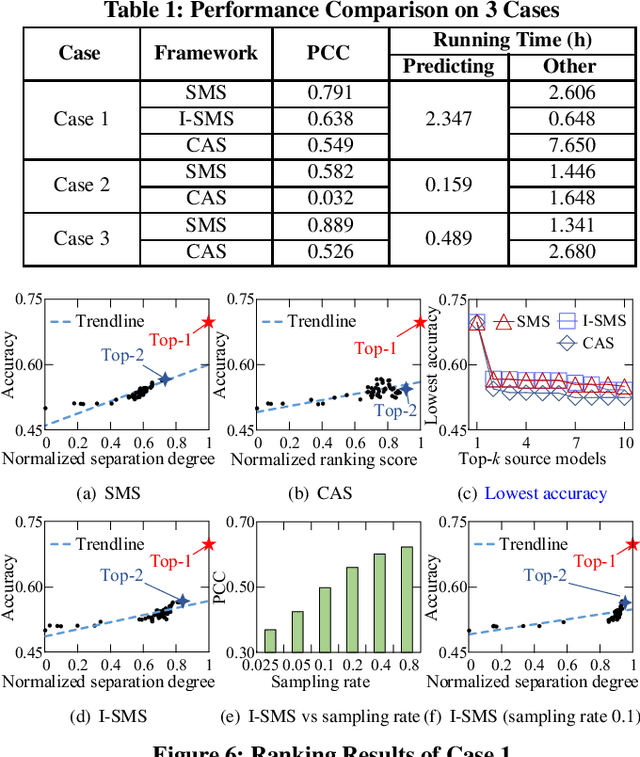

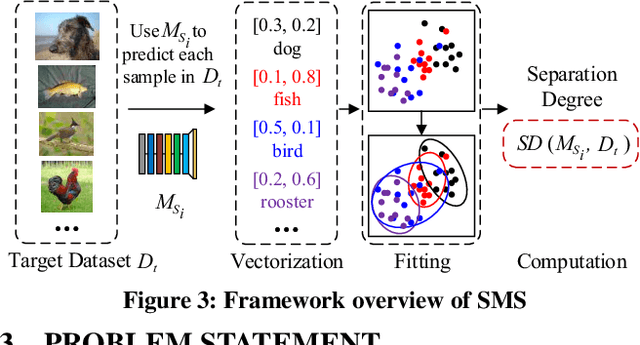
With the explosive increase of big data, training a Machine Learning (ML) model becomes a computation-intensive workload, which would take days or even weeks. Thus, model reuse has received attention in the ML community, where it is called transfer learning. Transfer learning avoids training a new model from scratch by transferring knowledge from a source task to a target task. Existing transfer learning methods mostly focus on how to improve the performance of the target task through a specific source model, and assume that the source model is given. Although many source models are available, it is difficult for data scientists to select the best source model for the target task manually. Hence, how to efficiently select a suitable source model for model reuse is still an unsolved problem. In this paper, we propose SMS, an effective, efficient and flexible source model selection framework. SMS is effective even when source and target datasets have significantly different data labels, is flexible to support source models with any type of structure, and is efficient to avoid any training process. For each source model, SMS first vectorizes the samples in the target dataset into soft labels by directly applying this model to the target dataset, then uses Gaussian distributions to fit for clusters of soft labels, and finally measures its distinguishing ability using Gaussian mixture-based metric. Moreover, we present an improved SMS (I-SMS), which decreases the output number of source model. I-SMS can significantly reduce the selection time while retaining the selection performance of SMS. Extensive experiments on a range of practical model reuse workloads demonstrate the effectiveness and efficiency of SMS.