 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing Proximal Gradient Method for General Structured Sparse Learning
Paper and Code
Feb 14, 2012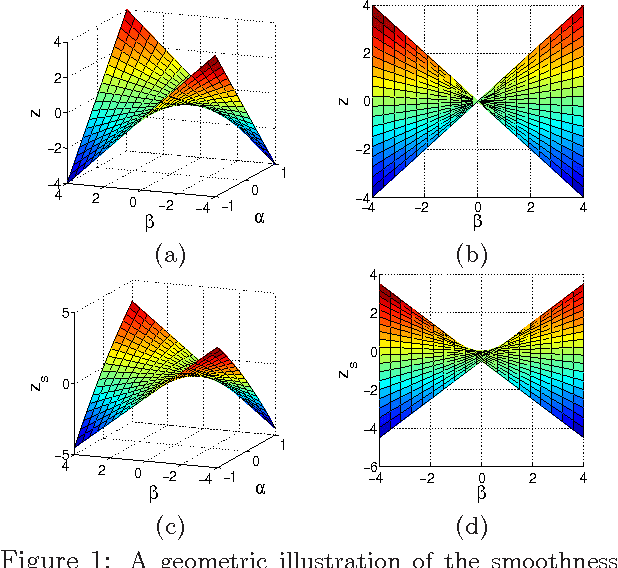
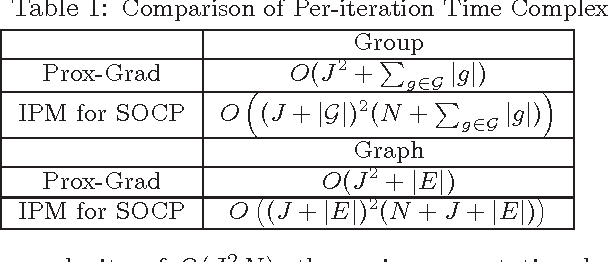
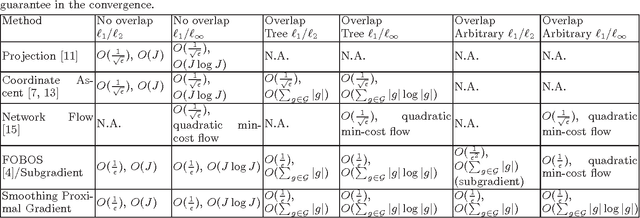
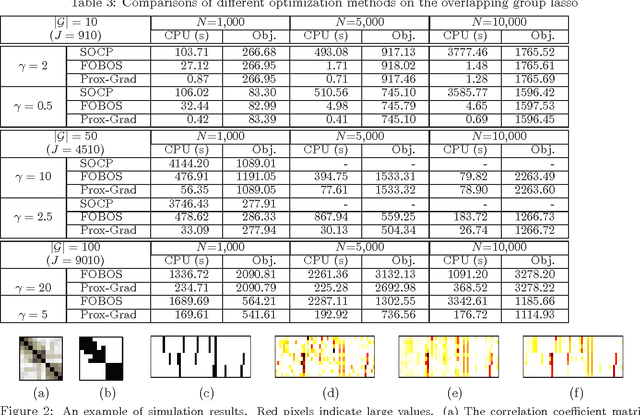
We study the problem of learning high dimensional regression models regularized by a structured-sparsity-inducing penalty that encodes prior structural information on either input or output sides. We consider two widely adopted types of such penalties as our motivating examples: 1) overlapping group lasso penalty, based on the l1/l2 mixed-norm penalty, and 2) graph-guided fusion penalty. For both types of penalties, due to their non-separability, developing an efficient optimization method has remained a challenging problem. In this paper, we propose a general optimization approach, called smoothing proximal gradient method, which can solve the structured sparse regression problems with a smooth convex loss and a wide spectrum of structured-sparsity-inducing penalties. Our approach is based on a general smoothing technique of Nesterov. It achieves a convergence rate faster than the standard first-order method, subgradient method, and is much more scalable than the most widely used interior-point method. Numerical results are reported to demonstrate the efficiency and scalability of the proposed method.