 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMiRL: Surprise Minimizing RL in Dynamic Environments
Paper and Code


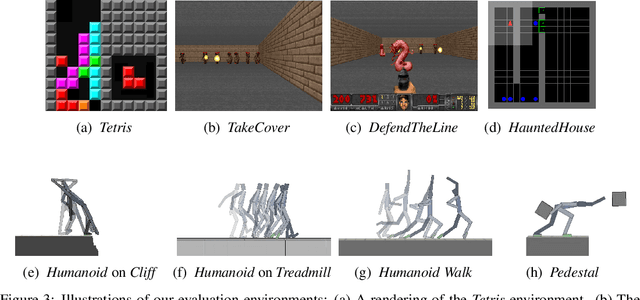
All living organisms struggle against the forces of nature to carve out niches where they can maintain homeostasis. We propose that such a search for order amidst chaos might offer a unifying principle for the emergence of useful behaviors in artificial agents. We formalize this idea into an unsupervised reinforcement learning method called surprise minimizing RL (SMiRL). SMiRL trains an agent with the objective of maximizing the probability of observed states under a model trained on previously seen states. The resulting agents can acquire proactive behaviors that seek out and maintain stable conditions, such as balancing and damage avoidance, that are closely tied to an environment's prevailing sources of entropy, such as wind, earthquakes, and other agents. We demonstrate that our surprise minimizing agents can successfully play Tetris, Doom, control a humanoid to avoid falls and navigate to escape enemy agents, without any task-specific reward supervision. We further show that SMiRL can be used together with a standard task reward to accelerate reward-driven learning.