 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSleeping Combinatorial Bandits
Paper and Code
Jun 03, 2021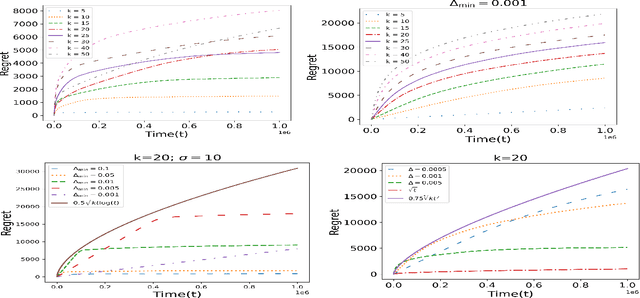

In this paper, we study an interesting combination of sleeping and combinatorial stochastic bandits. In the mixed model studied here, at each discrete time instant, an arbitrary \emph{availability set} is generated from a fixed set of \emph{base} arms. An algorithm can select a subset of arms from the \emph{availability set} (sleeping bandits) and receive the corresponding reward along with semi-bandit feedback (combinatorial bandits). We adapt the well-known CUCB algorithm in the sleeping combinatorial bandits setting and refer to it as \CSUCB. We prove -- under mild smoothness conditions -- that the \CSUCB\ algorithm achieves an $O(\log (T))$ instance-dependent regret guarantee. We further prove that (i) when the range of the rewards is bounded, the regret guarantee of \CSUCB\ algorithm is $O(\sqrt{T \log (T)})$ and (ii) the instance-independent regret is $O(\sqrt[3]{T^2 \log(T)})$ in a general setting. Our results are quite general and hold under general environments -- such as non-additive reward functions, volatile arm availability, a variable number of base-arms to be pulled -- arising in practical applications. We validate the proven theoretical guarantees through experiments.