 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAM-Safe Planner: Preventing Monocular SLAM Failure using Reinforcement Learning
Paper and Code
Mar 03, 2017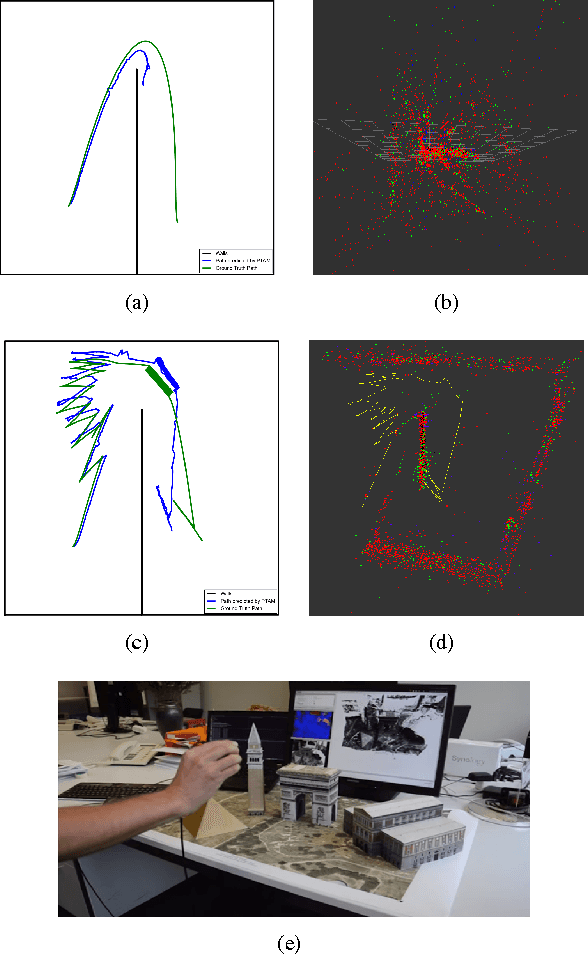
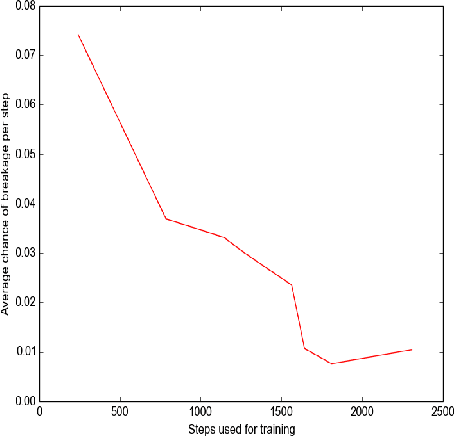

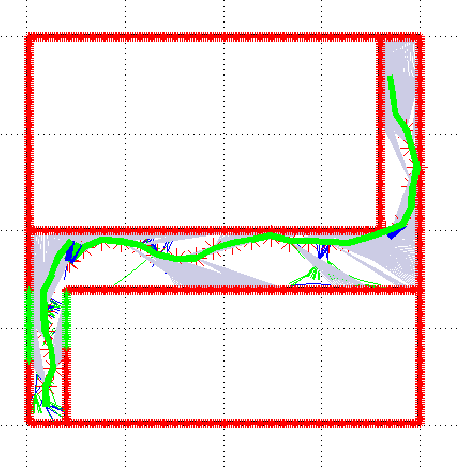
Effective SLAM using a single monocular camera is highly preferred due to its simplicity. However, when compared to trajectory planning methods using depth-based SLAM, Monocular SLAM in loop does need additional considerations. One main reason being that for the optimization, in the form of Bundle Adjustment (BA), to be robust, the SLAM system needs to scan the area for a reasonable duration. Most monocular SLAM systems do not tolerate large camera rotations between successive views and tend to breakdown. Other reasons for Monocular SLAM failure include ambiguities in decomposition of the Essential Matrix, feature-sparse scenes and more layers of non linear optimization apart from BA. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs (scene structure and camera motion) do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between motor actions and perceptual inputs that result in trajectories that do not cause failure of SLAM, which are almost intractable to capture in an obvious mathematical formulation. We show systematically in simulations how the quality of the SLAM map and trajectory dramatically improves when trajectories are computed by using RL.