 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketching Datasets for Large-Scale Learning (long version)
Paper and Code

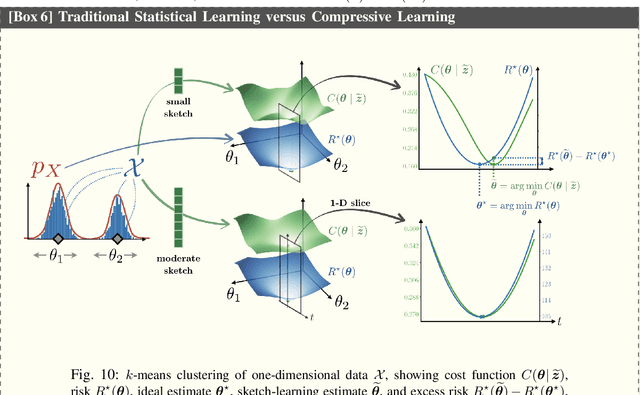

This article considers "sketched learning," or "compressive learning," an approach to large-scale machine learning where datasets are massively compressed before learning (e.g., clustering, classification, or regression) is performed. In particular, a "sketch" is first constructed by computing carefully chosen nonlinear random features (e.g., random Fourier features) and averaging them over the whole dataset. Parameters are then learned from the sketch, without access to the original dataset. This article surveys the current state-of-the-art in sketched learning, including the main concepts and algorithms, their connections with established signal-processing methods, existing theoretical guarantees---on both information preservation and privacy preservation, and important open problems.