 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Pass Entrywise-Transformed Low Rank Approximation
Paper and Code
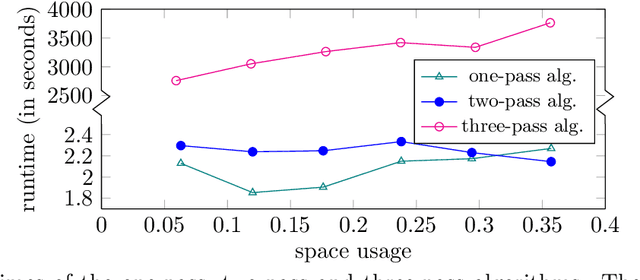
Jul 16, 2021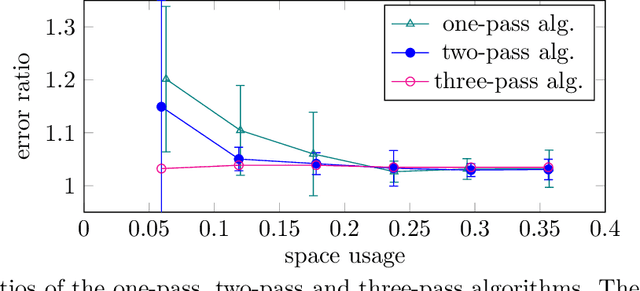
In applications such as natural language processing or computer vision, one is given a large $n \times d$ matrix $A = (a_{i,j})$ and would like to compute a matrix decomposition, e.g., a low rank approximation, of a function $f(A) = (f(a_{i,j}))$ applied entrywise to $A$. A very important special case is the likelihood function $f\left( A \right ) = \log{\left( \left| a_{ij}\right| +1\right)}$. A natural way to do this would be to simply apply $f$ to each entry of $A$, and then compute the matrix decomposition, but this requires storing all of $A$ as well as multiple passes over its entries. Recent work of Liang et al.\ shows how to find a rank-$k$ factorization to $f(A)$ for an $n \times n$ matrix $A$ using only $n \cdot \operatorname{poly}(\epsilon^{-1}k\log n)$ words of memory, with overall error $10\|f(A)-[f(A)]_k\|_F^2 + \operatorname{poly}(\epsilon/k) \|f(A)\|_{1,2}^2$, where $[f(A)]_k$ is the best rank-$k$ approximation to $f(A)$ and $\|f(A)\|_{1,2}^2$ is the square of the sum of Euclidean lengths of rows of $f(A)$. Their algorithm uses three passes over the entries of $A$. The authors pose the open question of obtaining an algorithm with $n \cdot \operatorname{poly}(\epsilon^{-1}k\log n)$ words of memory using only a single pass over the entries of $A$. In this paper we resolve this open question, obtaining the first single-pass algorithm for this problem and for the same class of functions $f$ studied by Liang et al. Moreover, our error is $\|f(A)-[f(A)]_k\|_F^2 + \operatorname{poly}(\epsilon/k) \|f(A)\|_F^2$, where $\|f(A)\|_F^2$ is the sum of squares of Euclidean lengths of rows of $f(A)$. Thus our error is significantly smaller, as it removes the factor of $10$ and also $\|f(A)\|_F^2 \leq \|f(A)\|_{1,2}^2$. We also give an algorithm for regression, pointing out an error in previous work, and empirically validate our results.