 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Us the Way: Learning to Manage Dialog from Demonstrations
Paper and Code
Apr 17, 2020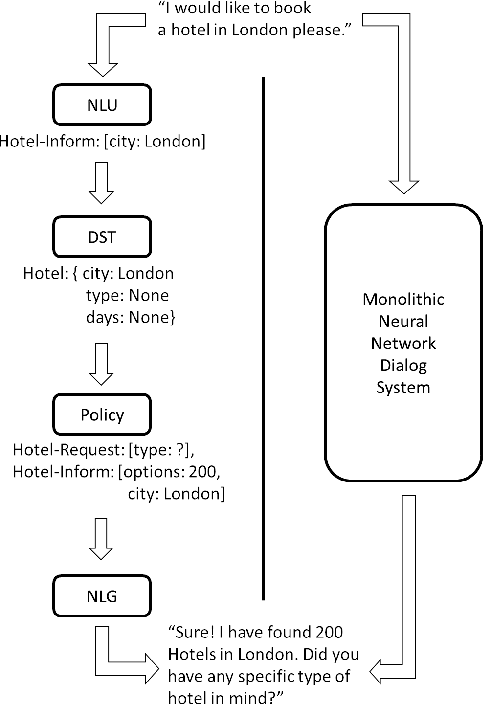
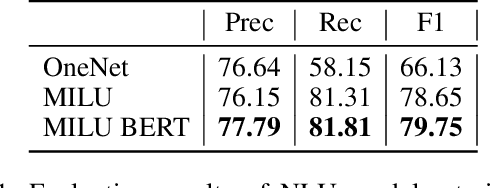

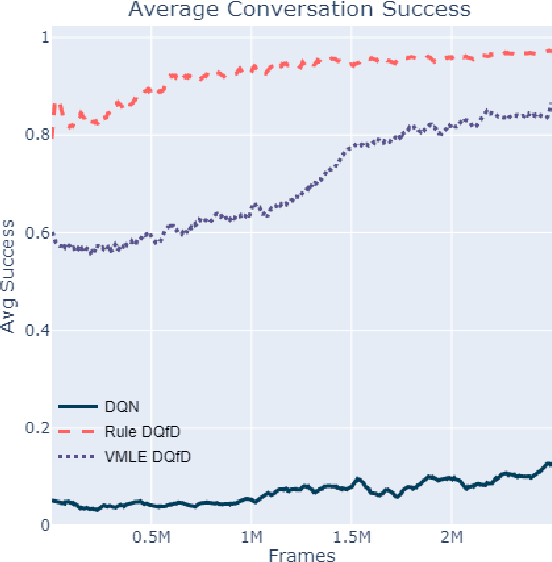
We present our submission to the End-to-End Multi-Domain Dialog Challenge Track of the Eighth Dialog System Technology Challenge. Our proposed dialog system adopts a pipeline architecture, with distinct components for Natural Language Understanding, Dialog State Tracking, Dialog Management and Natural Language Generation. At the core of our system is a reinforcement learning algorithm which uses Deep Q-learning from Demonstrations to learn a dialog policy with the help of expert examples. We find that demonstrations are essential to training an accurate dialog policy where both state and action spaces are large. Evaluation of our Dialog Management component shows that our approach is effective - beating supervised and reinforcement learning baselines.