 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-Net: Syntax-Guided Machine Reading Comprehension
Paper and Code

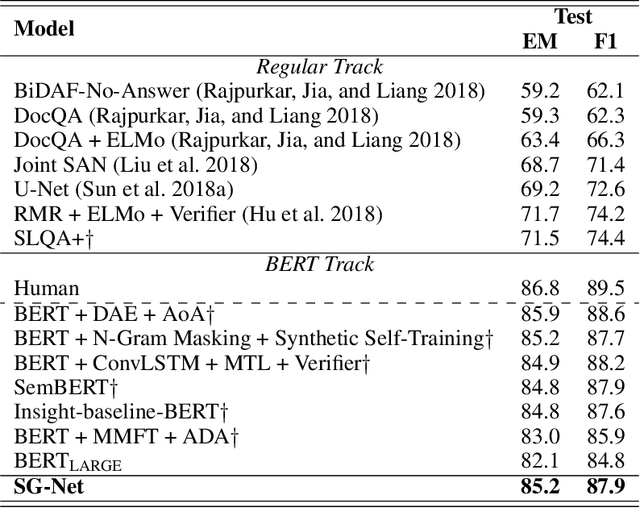
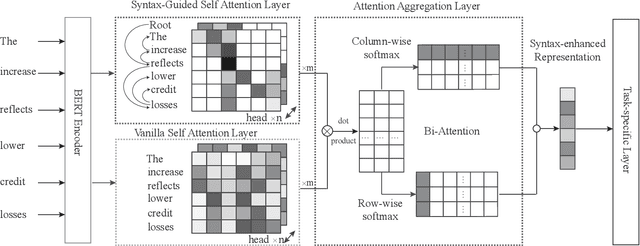
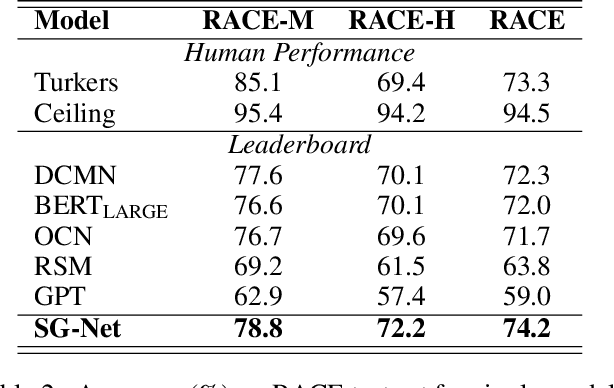
For machine reading comprehension, the capacity of effectively modeling the linguistic knowledge from the detail-riddled and lengthy passages and getting ride of the noises is essential to improve its performance. Traditional attentive models attend to all words without explicit constraint, which results in inaccurate concentration on some dispensable words. In this work, we propose using syntax to guide the text modeling of both passages and questions by incorporating explicit syntactic constraints into attention mechanism for better linguistically motivated word representations. To serve such a purpose, we propose a novel dual contextual architecture called syntax-guided network (SG-Net), which consists of a BERT context vector and a syntax-guided context vector, to provide more fine-grained representation. Extensive experiments on popular benchmarks including SQuAD 2.0 and RACE show that the proposed approach achieves a substantial and significant improvement over the fine-tuned BERT baseline.