 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Contrastive Learning with Similarity Co-calibration
Paper and Code
May 16, 2021
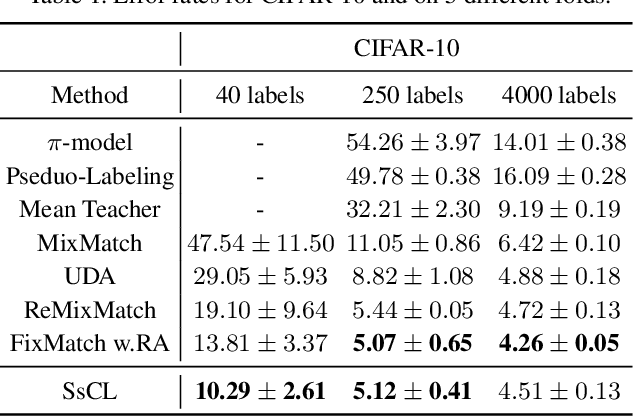


Semi-supervised learning acts as an effective way to leverage massive unlabeled data. In this paper, we propose a novel training strategy, termed as Semi-supervised Contrastive Learning (SsCL), which combines the well-known contrastive loss in self-supervised learning with the cross entropy loss in semi-supervised learning, and jointly optimizes the two objectives in an end-to-end way. The highlight is that different from self-training based semi-supervised learning that conducts prediction and retraining over the same model weights, SsCL interchanges the predictions over the unlabeled data between the two branches, and thus formulates a co-calibration procedure, which we find is beneficial for better prediction and avoid being trapped in local minimum. Towards this goal, the contrastive loss branch models pairwise similarities among samples, using the nearest neighborhood generated from the cross entropy branch, and in turn calibrates the prediction distribution of the cross entropy branch with the contrastive similarity. We show that SsCL produces more discriminative representation and is beneficial to few shot learning. Notably, on ImageNet with ResNet50 as the backbone, SsCL achieves 60.2% and 72.1% top-1 accuracy with 1% and 10% labeled samples, respectively, which significantly outperforms the baseline, and is better than previous semi-supervised and self-supervised methods.