 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Paper and Code
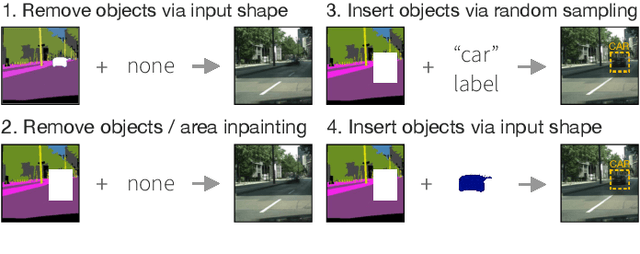



Manipulating images of complex scenes to reconstruct, insert and/or remove specific object instances is a challenging task. Complex scenes contain multiple semantics and objects, which are frequently cluttered or ambiguous, thus hampering the performance of inpainting models. Conventional techniques often rely on structural information such as object contours in multi-stage approaches that generate unreliable results and boundaries. In this work, we propose a novel deep learning model to alter a complex urban scene by removing a user-specified portion of the image and coherently inserting a new object (e.g. car or pedestrian) in that scene. Inspired by recent works on image inpainting, our proposed method leverages the semantic segmentation to model the content and structure of the image, and learn the best shape and location of the object to insert. To generate reliable results, we design a new decoder block that combines the semantic segmentation and generation task to guide better the generation of new objects and scenes, which have to be semantically consistent with the image. Our experiments, conducted on two large-scale datasets of urban scenes (Cityscapes and Indian Driving), show that our proposed approach successfully address the problem of semantically-guided inpainting of complex urban scene.