 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Point Cloud Prediction Using 3D Spatio-temporal Convolutional Networks
Paper and Code
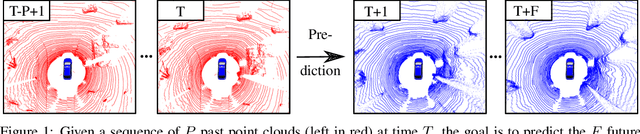

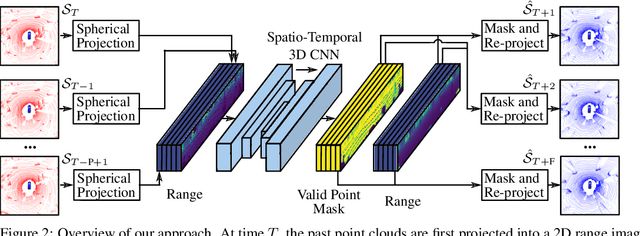
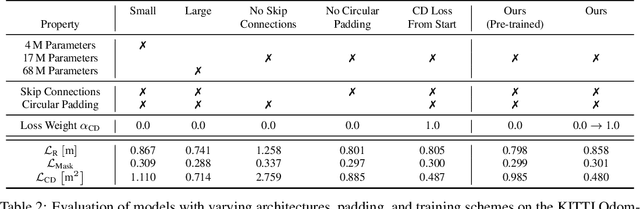
Exploiting past 3D LiDAR scans to predict future point clouds is a promising method for autonomous mobile systems to realize foresighted state estimation, collision avoidance, and planning. In this paper, we address the problem of predicting future 3D LiDAR point clouds given a sequence of past LiDAR scans. Estimating the future scene on the sensor level does not require any preceding steps as in localization or tracking systems and can be trained self-supervised. We propose an end-to-end approach that exploits a 2D range image representation of each 3D LiDAR scan and concatenates a sequence of range images to obtain a 3D tensor. Based on such tensors, we develop an encoder-decoder architecture using 3D convolutions to jointly aggregate spatial and temporal information of the scene and to predict the future 3D point clouds. We evaluate our method on multiple datasets and the experimental results suggest that our method outperforms existing point cloud prediction architectures and generalizes well to new, unseen environments without additional fine-tuning. Our method operates online and is faster than the common LiDAR frame rate of 10 Hz.