 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning for Semi-supervised Temporal Language Grounding
Paper and Code
Sep 23, 2021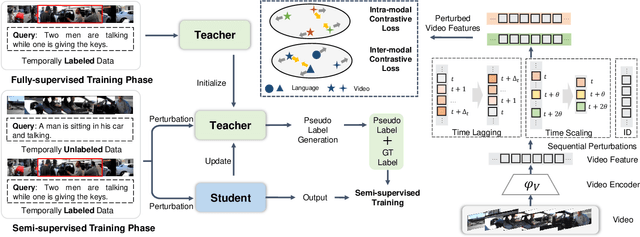



Given a text description, Temporal Language Grounding (TLG) aims to localize temporal boundaries of the segments that contain the specified semantics in an untrimmed video. TLG is inherently a challenging task, as it requires to have comprehensive understanding of both video contents and text sentences. Previous works either tackle this task in a fully-supervised setting that requires a large amount of manual annotations or in a weakly supervised setting that cannot achieve satisfactory performance. To achieve good performance with limited annotations, we tackle this task in a semi-supervised way and propose a unified Semi-supervised Temporal Language Grounding (STLG) framework. STLG consists of two parts: (1) A pseudo label generation module that produces adaptive instant pseudo labels for unlabeled data based on predictions from a teacher model; (2) A self-supervised feature learning module with two sequential perturbations, i.e., time lagging and time scaling, for improving the video representation by inter-modal and intra-modal contrastive learning. We conduct experiments on the ActivityNet-CD-OOD and Charades-CD-OOD datasets and the results demonstrate that our proposed STLG framework achieve competitive performance compared to fully-supervised state-of-the-art methods with only a small portion of temporal annotations.