 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Expressing Autoencoders for Unsupervised Spoken Term Discovery
Paper and Code
Jul 26, 2020
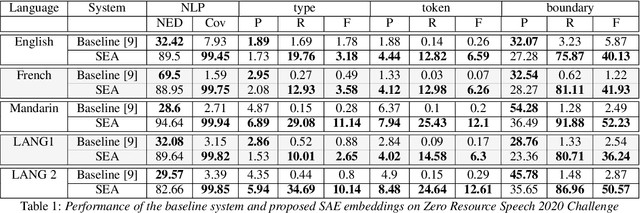
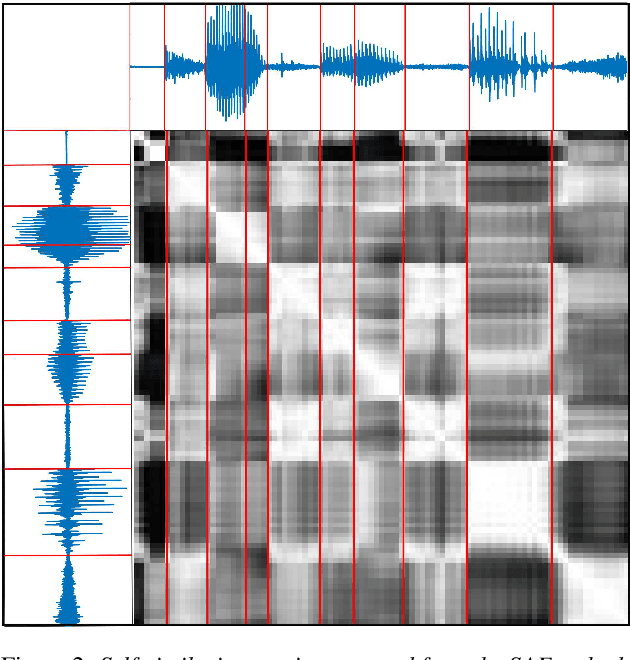
Unsupervised spoken term discovery consists of two tasks: finding the acoustic segment boundaries and labeling acoustically similar segments with the same labels. We perform segmentation based on the assumption that the frame feature vectors are more similar within a segment than across the segments. Therefore, for strong segmentation performance, it is crucial that the features represent the phonetic properties of a frame more than other factors of variability. We achieve this via a self-expressing autoencoder framework. It consists of a single encoder and two decoders with shared weights. The encoder projects the input features into a latent representation. One of the decoders tries to reconstruct the input from these latent representations and the other from the self-expressed version of them. We use the obtained features to segment and cluster the speech data. We evaluate the performance of the proposed method in the Zero Resource 2020 challenge unit discovery task. The proposed system consistently outperforms the baseline, demonstrating the usefulness of the method in learning representations.