 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attentive Document Interaction Networks for Permutation Equivariant Ranking
Paper and Code
Oct 23, 2019
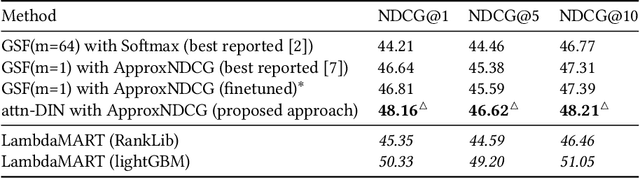
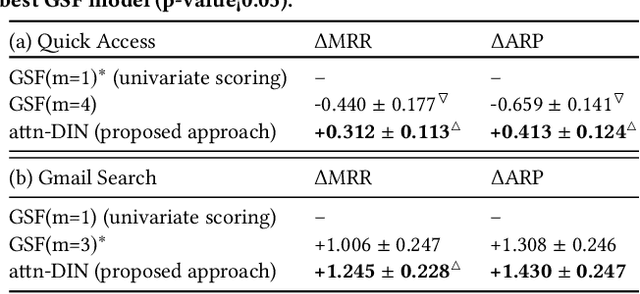
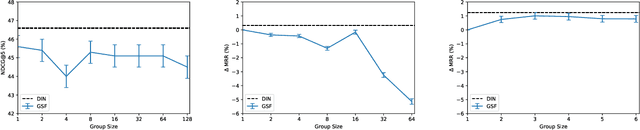
How to leverage cross-document interactions to improve ranking performance is an important topic in information retrieval (IR) research. However, this topic has not been well-studied in the learning-to-rank setting and most of the existing work still treats each document independently while scoring. The recent development of deep learning shows strength in modeling complex relationships across sequences and sets. It thus motivates us to study how to leverage cross-document interactions for learning-to-rank in the deep learning framework. In this paper, we formally define the permutation-equivariance requirement for a scoring function that captures cross-document interactions. We then propose a self-attention based document interaction network and show that it satisfies the permutation-equivariant requirement, and can generate scores for document sets of varying sizes. Our proposed methods can automatically learn to capture document interactions without any auxiliary information, and can scale across large document sets. We conduct experiments on three ranking datasets: the benchmark Web30k, a Gmail search, and a Google Drive Quick Access dataset. Experimental results show that our proposed methods are both more effective and efficient than baselines.