 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Attention Networks Can Process Bounded Hierarchical Languages
Paper and Code


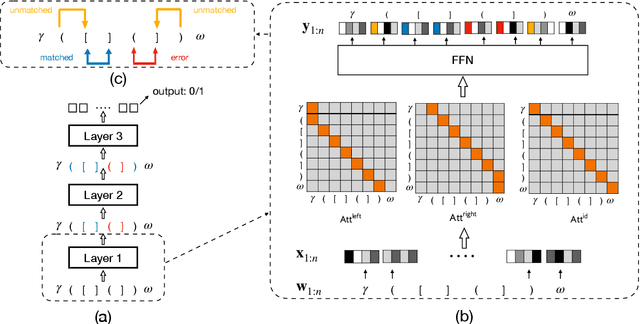
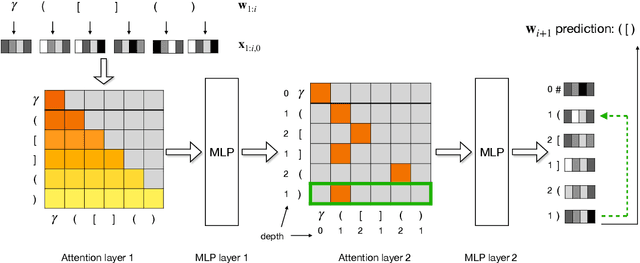
Despite their impressive performance in NLP, self-attention networks were recently proved to be limited for processing formal languages with hierarchical structure, such as $\mathsf{Dyck}_k$, the language consisting of well-nested parentheses of $k$ types. This suggested that natural language can be approximated well with models that are too weak for formal languages, or that the role of hierarchy and recursion in natural language might be limited. We qualify this implication by proving that self-attention networks can process $\mathsf{Dyck}_{k, D}$, the subset of $\mathsf{Dyck}_{k}$ with depth bounded by $D$, which arguably better captures the bounded hierarchical structure of natural language. Specifically, we construct a hard-attention network with $D+1$ layers and $O(\log k)$ memory size (per token per layer) that recognizes $\mathsf{Dyck}_{k, D}$, and a soft-attention network with two layers and $O(\log k)$ memory size that generates $\mathsf{Dyck}_{k, D}$. Experiments show that self-attention networks trained on $\mathsf{Dyck}_{k, D}$ generalize to longer inputs with near-perfect accuracy, and also verify the theoretical memory advantage of self-attention networks over recurrent networks.