 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Knowledge Distillation for Neural Machine Translation
Paper and Code



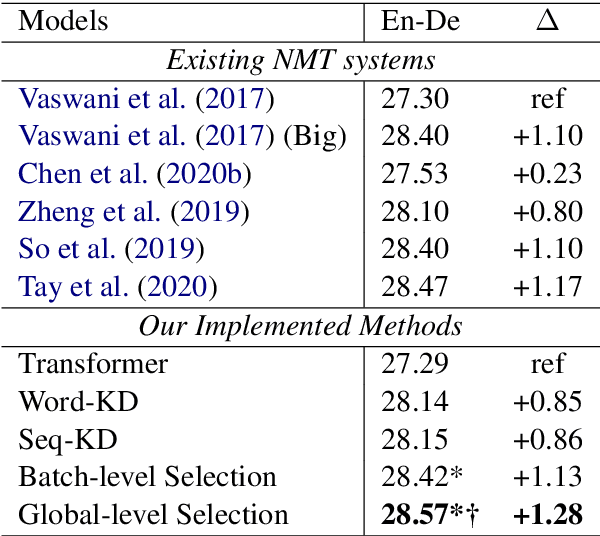
Neural Machine Translation (NMT) models achieve state-of-the-art performance on many translation benchmarks. As an active research field in NMT, knowledge distillation is widely applied to enhance the model's performance by transferring teacher model's knowledge on each training sample. However, previous work rarely discusses the different impacts and connections among these samples, which serve as the medium for transferring teacher knowledge. In this paper, we design a novel protocol that can effectively analyze the different impacts of samples by comparing various samples' partitions. Based on above protocol, we conduct extensive experiments and find that the teacher's knowledge is not the more, the better. Knowledge over specific samples may even hurt the whole performance of knowledge distillation. Finally, to address these issues, we propose two simple yet effective strategies, i.e., batch-level and global-level selections, to pick suitable samples for distillation. We evaluate our approaches on two large-scale machine translation tasks, WMT'14 English->German and WMT'19 Chinese->English. Experimental results show that our approaches yield up to +1.28 and +0.89 BLEU points improvements over the Transformer baseline, respectively.