 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Treatment Effects Models for Domain Adaptation Using Causal Knowledge
Paper and Code
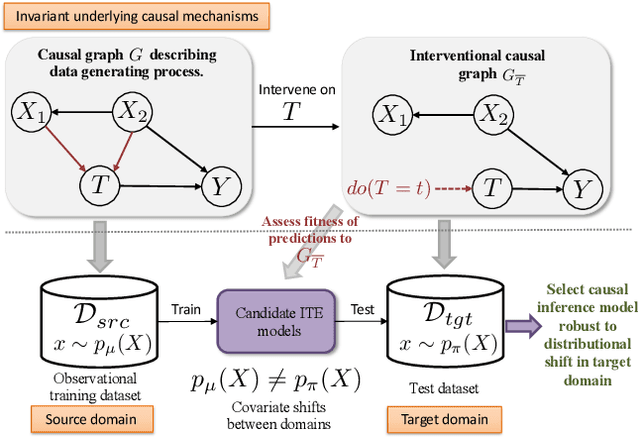
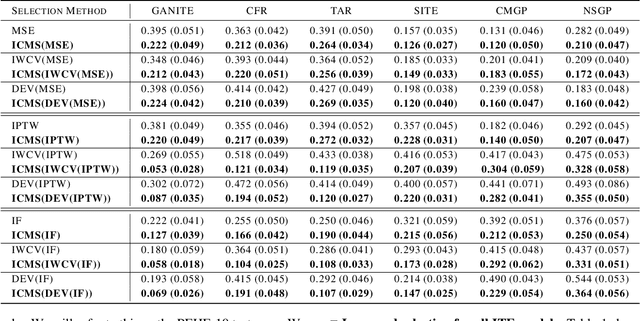


Selecting causal inference models for estimating individualized treatment effects (ITE) from observational data presents a unique challenge since the counterfactual outcomes are never observed. The problem is challenged further in the unsupervised domain adaptation (UDA) setting where we only have access to labeled samples in the source domain, but desire selecting a model that achieves good performance on a target domain for which only unlabeled samples are available. Existing techniques for UDA model selection are designed for the predictive setting. These methods examine discriminative density ratios between the input covariates in the source and target domain and do not factor in the model's predictions in the target domain. Because of this, two models with identical performance on the source domain would receive the same risk score by existing methods, but in reality, have significantly different performance in the test domain. We leverage the invariance of causal structures across domains to propose a novel model selection metric specifically designed for ITE methods under the UDA setting. In particular, we propose selecting models whose predictions of interventions' effects satisfy known causal structures in the target domain. Experimentally, our method selects ITE models that are more robust to covariate shifts on several healthcare datasets, including estimating the effect of ventilation in COVID-19 patients from different geographic locations.