 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing The Whole Patient: Using Multi-Label Medical Text Classification Techniques to Enhance Predictions of Medical Codes
Paper and Code
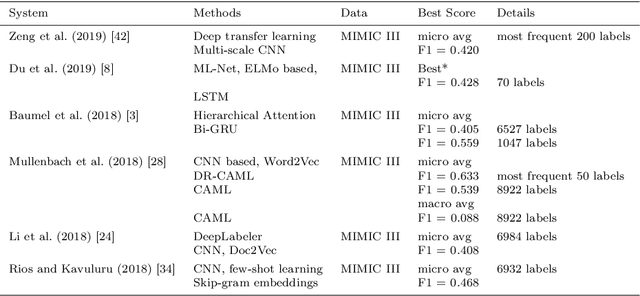
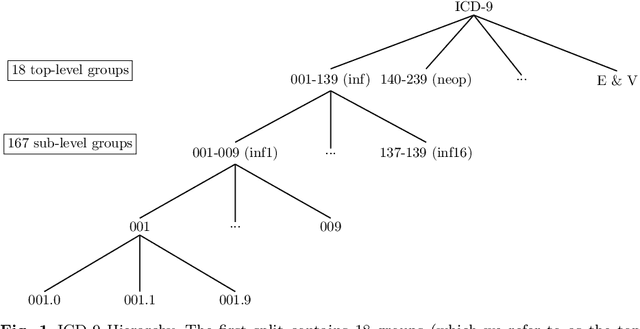
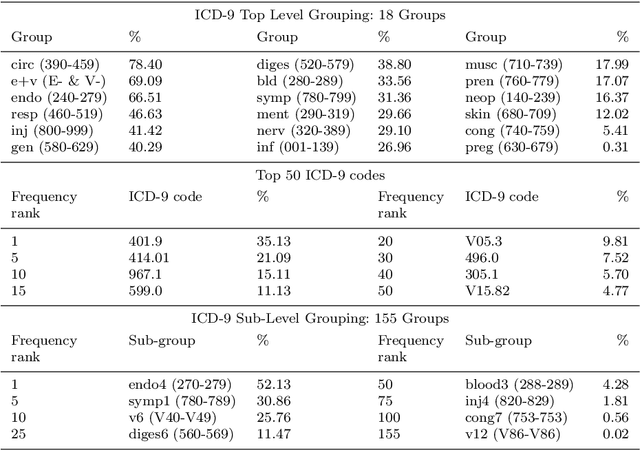

Machine learning-based multi-label medical text classifications can be used to enhance the understanding of the human body and aid the need for patient care. We present a broad study on clinical natural language processing techniques to maximise a feature representing text when predicting medical codes on patients with multi-morbidity. We present results of multi-label medical text classification problems with 18, 50 and 155 labels. We compare several variations to embeddings, text tagging, and pre-processing. For imbalanced data we show that labels which occur infrequently, benefit the most from additional features incorporated in embeddings. We also show that high dimensional embeddings pre-trained using health-related data present a significant improvement in a multi-label setting, similarly to the way they improve performance for binary classification. High dimensional embeddings from this research are made available for public use.