 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAN: Self-and-Collaborative Attention Network for Video Person Re-identification
Paper and Code
Jul 20, 2018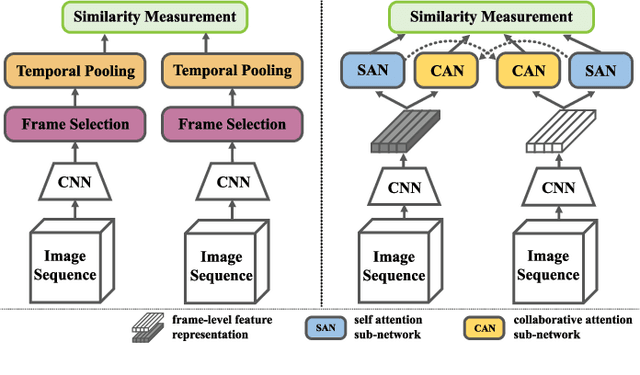
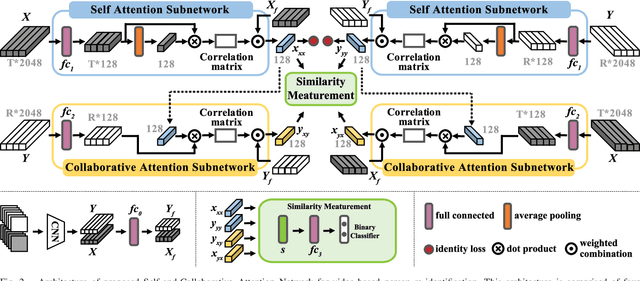
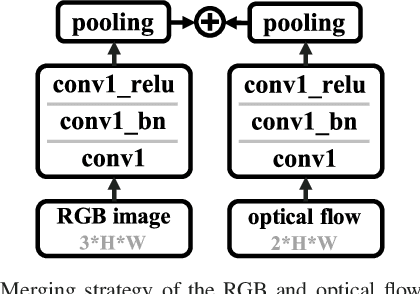
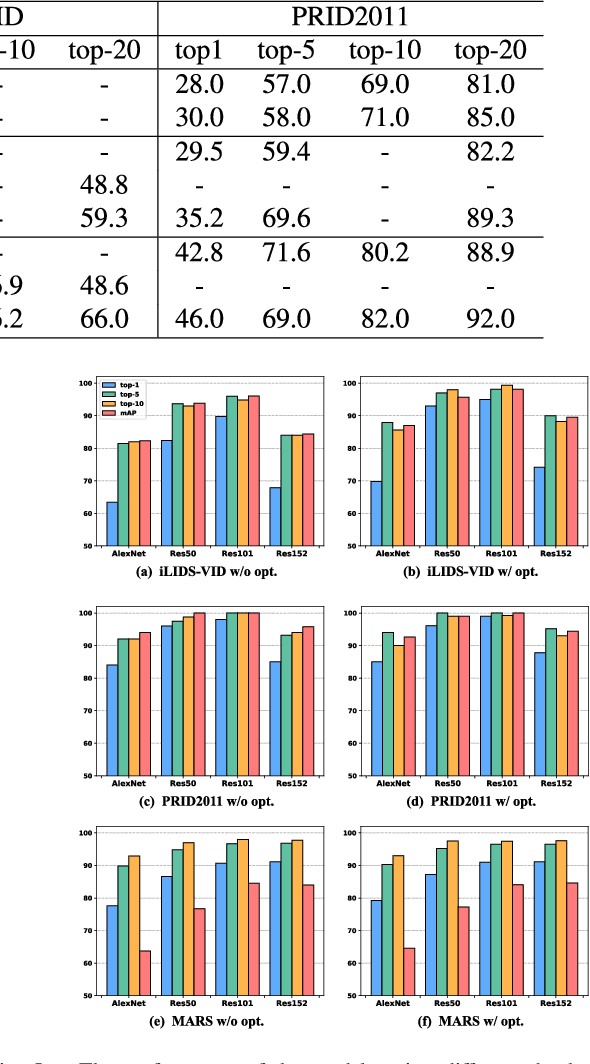
Video person re-identification attracts much attention in recent years. It aims to match image sequences of pedestrians from different camera views. Previous approaches usually improve this task from three aspects, including a) selecting more discriminative frames, b) generating more informative temporal representations, and c) developing more effective distance metrics. To address the above issues, we present a novel and practical deep architecture for video person re-identification termed Self-and-Collaborative Attention Network (SCAN). It has several appealing properties. First, SCAN adopts non-parametric attention mechanism to refine the intra-sequence and inter-sequence feature representation of videos, and outputs self-and-collaborative feature representation for each video, making the discriminative frames aligned between the probe and gallery sequences.Second, beyond existing models, a generalized pairwise similarity measurement is proposed to calculate the similarity feature representations of video pairs, enabling computing the matching scores by the binary classifier. Third, a dense clip segmentation strategy is also introduced to generate rich probe-gallery pairs to optimize the model. Extensive experiments demonstrate the effectiveness of SCAN, which outperforms top-1 accuracies of the best-performing baselines by 7.8%, 2.1% and 4.9% on iLIDS-VID, PRID2011 and MARS dataset, respectively.