 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Semi-Supervised Learning over Networks using Nonsmooth Convex Optimization
Paper and Code
Nov 02, 2016
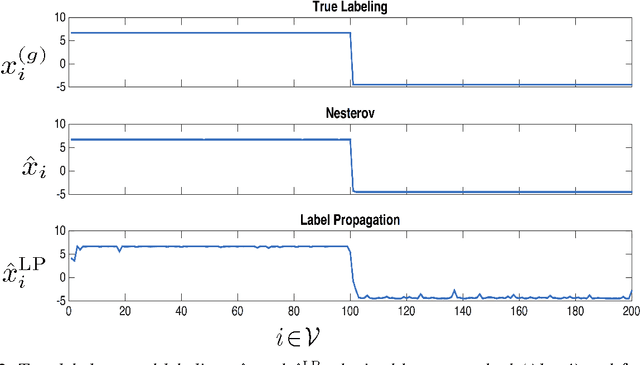
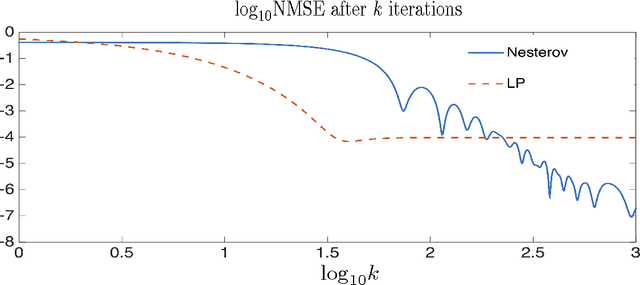
We propose a scalable method for semi-supervised (transductive) learning from massive network-structured datasets. Our approach to semi-supervised learning is based on representing the underlying hypothesis as a graph signal with small total variation. Requiring a small total variation of the graph signal representing the underlying hypothesis corresponds to the central smoothness assumption that forms the basis for semi-supervised learning, i.e., input points forming clusters have similar output values or labels. We formulate the learning problem as a nonsmooth convex optimization problem which we solve by appealing to Nesterovs optimal first-order method for nonsmooth optimization. We also provide a message passing formulation of the learning method which allows for a highly scalable implementation in big data frameworks.